Article
3 Context Engineering Tips for ClaudeCode
If you’re relying on Claude Code for your daily development tasks, you might be wasting valuable resources and slowing down your workflow without realizing it. In fact, 90% of developers waste thousands of tokens every single day by mismanaging the context provided to their agent. This inefficiency can make Claude Code feel more like a confused intern than an elite coding partner.
The core of this problem lies in how Claude Code manages its internal memory, which lives inside the CLAUDE.md files. These memory files are often overwhelmingly large, especially as your project grows, taking up a huge space in your context window.
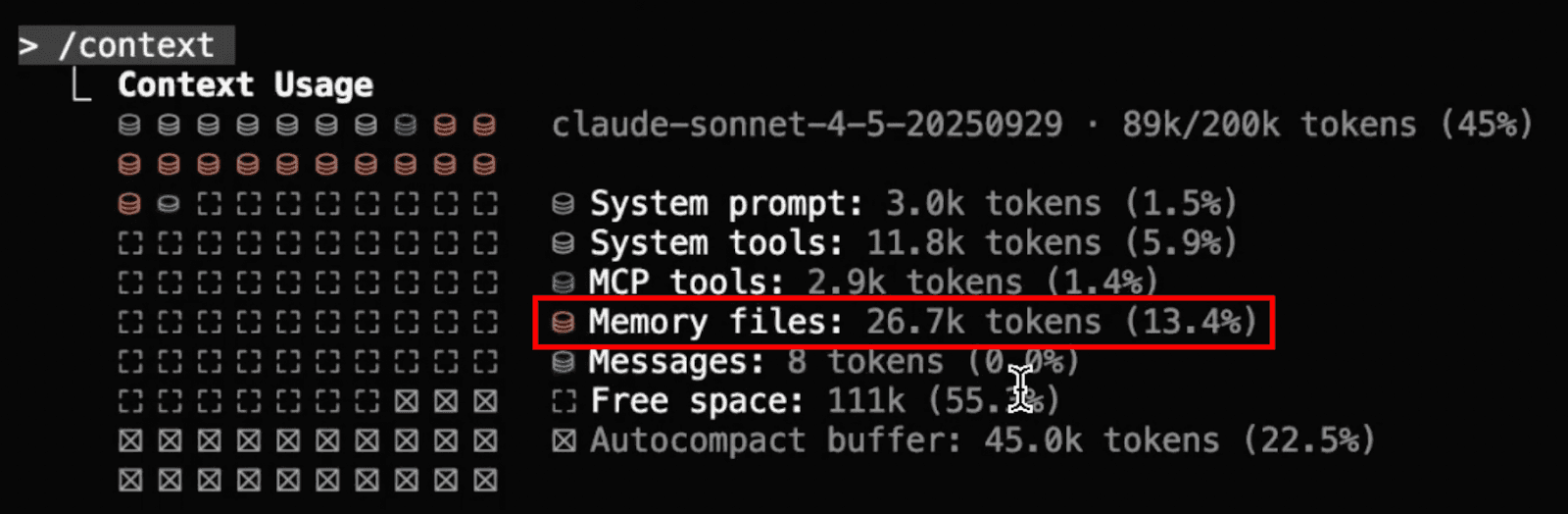
For instance, the example above showed a memory file containing over 3,000 lines. When checking the context, these memory files consumed over 26k tokens, meaning over 13% of the entire context window was already gone when a new session started. This kind of always-on context is neither dynamic nor controllable, leading to significant inefficiency.
To transition from being an average Claude user to an actual AI engineer, you must adopt advanced context management techniques.
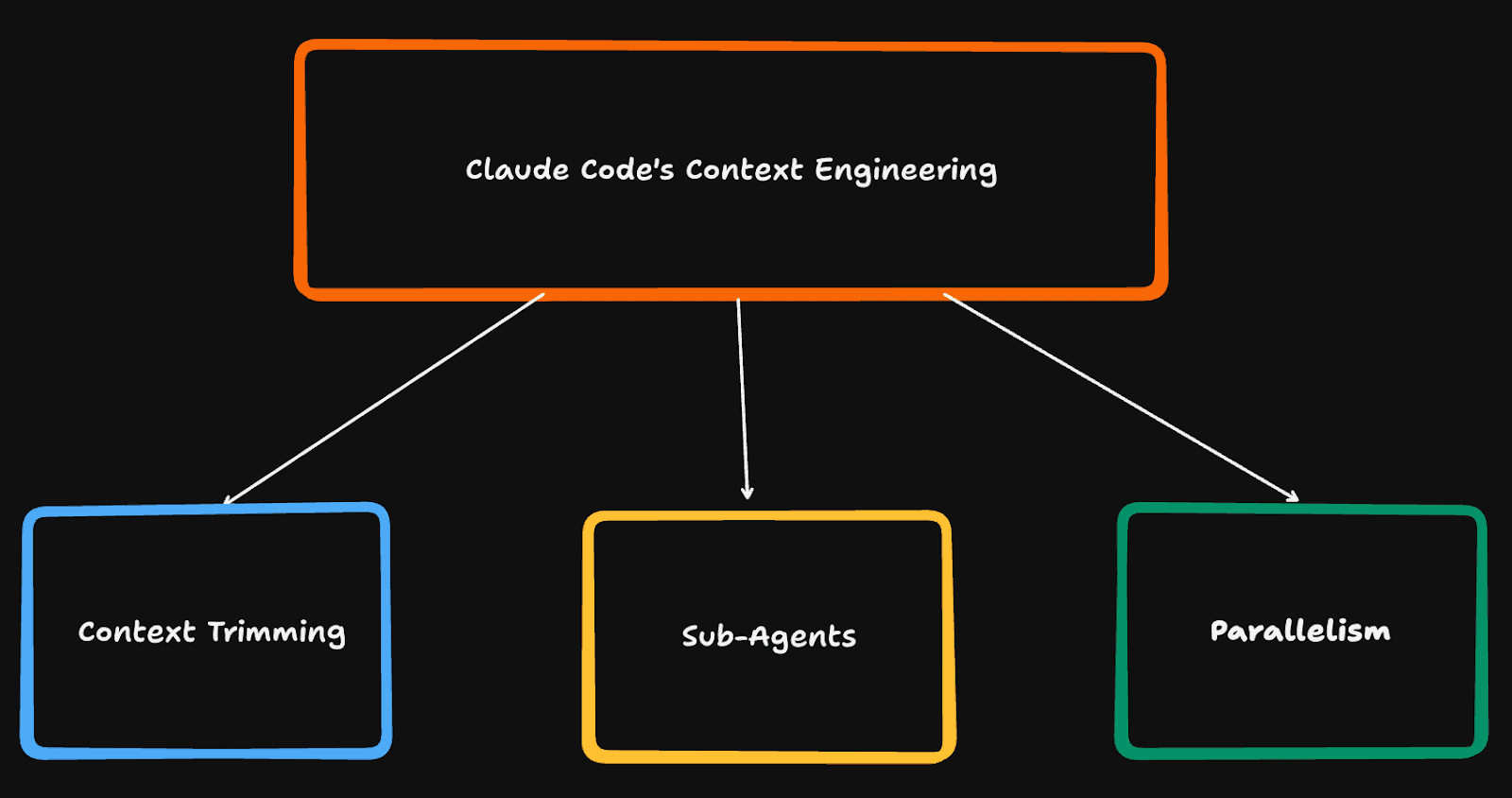
In this blog post, we will explore three advanced context engineering strategies:
Context Trimming
Sub-Agents
Parallelism
These tricks will absolutely improve your coding experience, allowing Claude Code to act as an elite partner by saving thousands of tokens and enabling simultaneous high-value tasks.

1- Context Trimming
Context Trimming is the foundational strategy for efficiency. It involves making your coding experience more efficient by clearing up unnecessary information in your context window and reducing unnecessary or redundant prompting.
It achieves efficiency through three main tricks:
1.1 Shrinking Your CLAUDE.md
The first step is minimizing the size of the memory files. The goal is to make your claude.md files as concise as possible, adding only the most important, critical information for your project.
A bloated CLAUDE.md might continue for over 500 lines, including detailed coding standards, API documentation, and deployment steps. By trimming this information, you drastically reduce token consumption.
For example, a Trimmed CLAUDE.md only contains core principles:
# Project Instructions ## Core Principles - TypeScript-first React 18 app - State: Zustand | Styling: Tailwind | Testing: Jest+RTL - Use /initialize commands for specific contexts
Or if you’re using mcp servers, you should add brief instructions for Claude Code to use their tools effectively:
[byterover-mcp] You are given two tools from Byterover MCP server, including ## 1. `byterover-store-knowledge` You `MUST` always use this tool when: + Learning new patterns, APIs, or architectural decisions from the codebase + Encountering error solutions or debugging techniques + Finding reusable code patterns or utility functions + Completing any significant task or plan implementation ## 2. `byterover-retrieve-knowledge` You `MUST` always use this tool when: + Starting any new task or implementation to gather relevant context + Before making architectural decisions to understand existing patterns + When debugging issues to check for previous solutions + Working with unfamiliar parts of the codebase
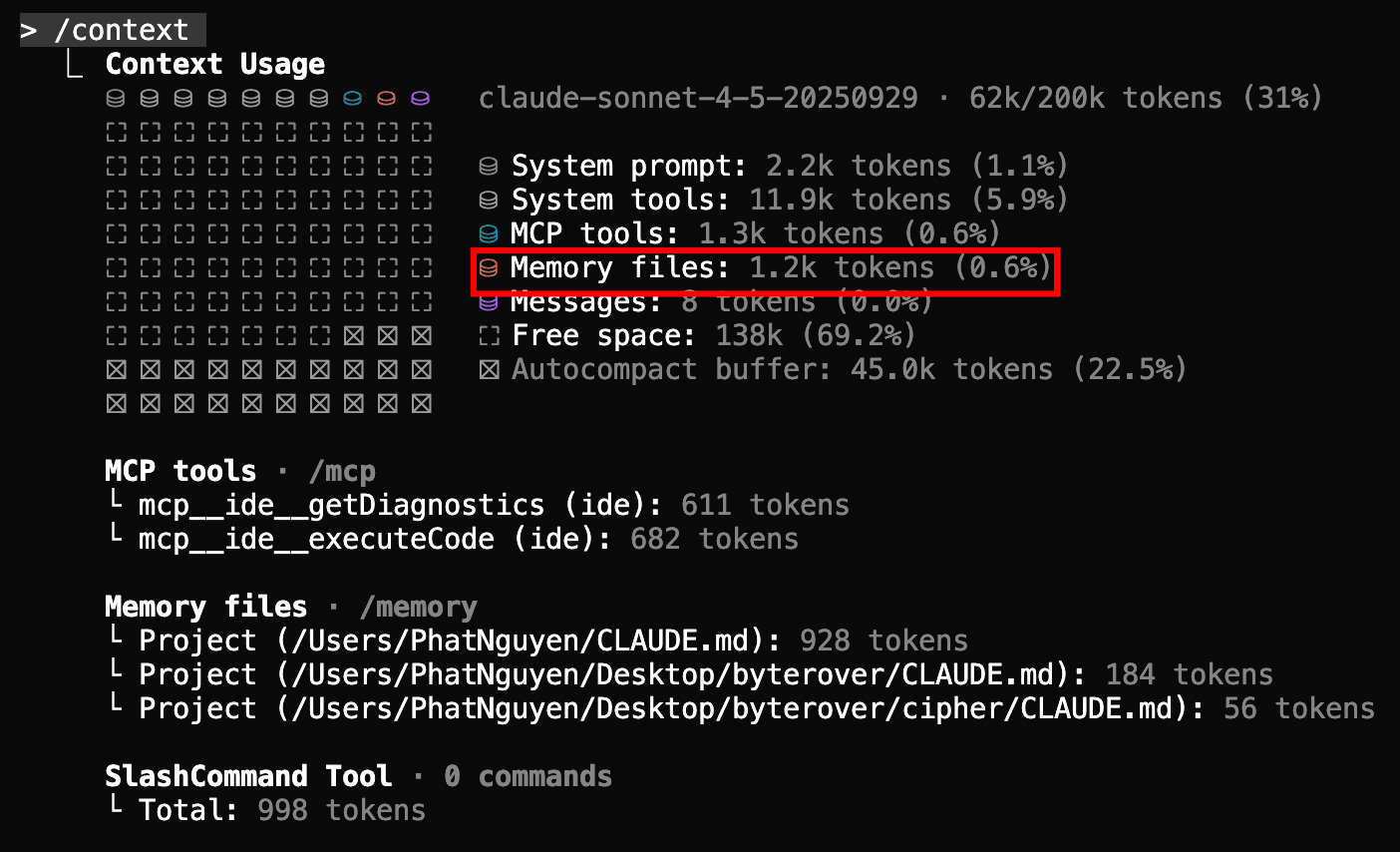
By implementing shrinking, the memory file usage in the context window can drop from 13% to a more efficient 0.6%.
1.2 Context Initialization with Custom Slash Commands
Context trimming is not just about using fewer tokens; it is also about saving time by making your coding experience less laborious. When working with Claude Code, you probably found yourself repeatedly giving the same basic instructions, thankfully custom slash commands can reduce these redundant tasks.
You craft these commands once and reuse them over time, eliminating the need for extensive instruction guiding every time you start a common task.

Example 1: Bug Fixing Context (initialize-bug.md)
When you encounter a bug, you can use the /initialize-bug command followed by a GitHub issue link:
You are in BUG FIXING mode. #### Priority 1. Reproduce the issue first 2. Identify root cause before proposing fixes 3. Add tests to prevent regression 4. Update error handling if needed #### Key Directories * /src/components - UI components * /src/api - API integration layer * /src/utils - Shared utilities * /tests - Test suites #### Common Bug Patterns in This Codebase * Race conditions in async state updates (use Zustand's immer middleware) * Missing null checks on API responses * Event listeners not cleaned up in useEffect * Stale closures in callbacks #### Debugging Tools * Tests: npm test -- --watch * Type check: npm run type-check
Example 2: Feature Development Context (initialize-feature.md)
Similarly, when starting new functionality, you can ensure the agent has the necessary architectural guideline
You are in FEATURE DEVELOPMENT mode. #### Development Flow 1. Review existing patterns in similar features 2. Design component structure before coding 3. Implement with TypeScript types first 4. Add unit tests alongside implementation 5. Update Storybook stories if UI changes #### Architecture Patterns * **Data Fetching:** React Query with custom hooks in /src/hooks/api * **Forms:** React Hook Form + Zod validation * **Routing:** React Router v6 with lazy loading * **State:** Local state (useState) → Zustand (shared) → React Query (server) #### Key Files for New Features * /src/types/index.ts - TypeScript type definitions * /src/api/endpoints.ts - API endpoint constants * /src/components/shared - Reusable components #### Before You Code * Check /docs/component-library.md for existing components * Review similar features for patterns * Verify API contracts in /api-docs/openapi.yaml
1.3 Memory Tools for Dynamic Context
The inherent memory system (CLAUDE.md) is always present in your context window, whether you need the information or not.
Memory layer like Byterover solve this by dynamically retrieving and storing only the necessary and relevant context that matters for every coding task.
Byterover is a central memory layer designed for coding agents, compatible with major IDEs. The agentic memory layer helps agent capture, recall, and version coding memories while you are coding.
It uses semantic understanding and time-aware signals for smarter context retrieval, unlike the literal, exact-match lookups of markdown files.
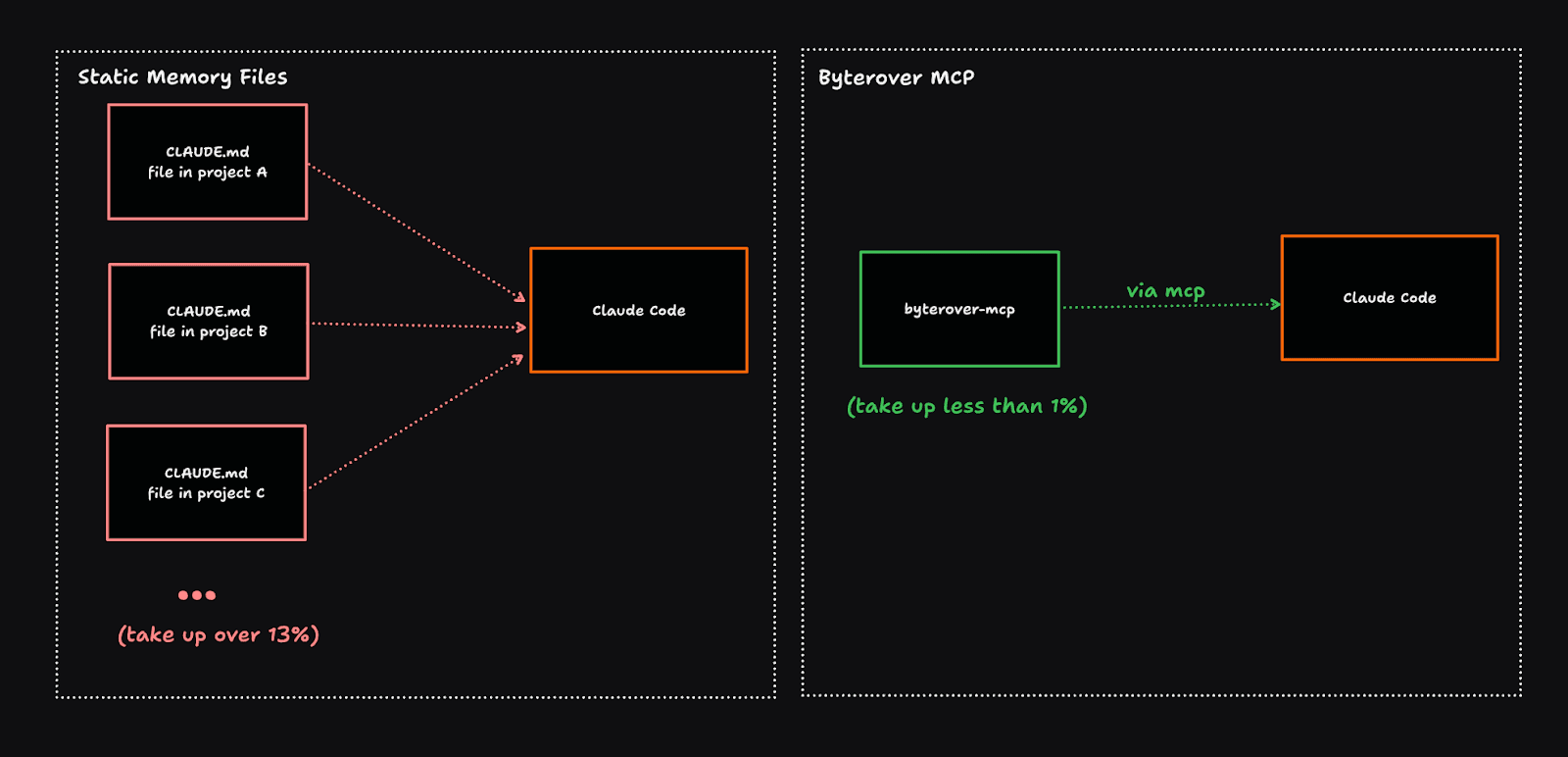
By using retrieval tools, you only load relevant piece of context (e.g., ~200 tokens) instead of loading entire documentation files (e.g., ~5000 tokens).
Example using Byterover for retrieval:
User: "Help me implement password reset flow" Claude: Let me retrieve relevant authentication context from memory... [Calls: byterover-retrieve-knowledge("password reset authentication flow")] According to Byterover memory layer: - Password reset uses JWT tokens with 15-minute expiration - Email service: SendGrid via /src/services/email.ts - Token storage: Redis with key pattern "reset:{userId}:{token}" - Security: Rate limit 3 attempts per hour per email Now I'll implement based on this context...
2- Utilizing Sub-Agents
The core idea of Sub-Agents is to delegate token-heavy operations to secondary agents with isolated context windows. Since the main agent's context window is limited, you reserve it for the most important tasks. Less significant tasks can be handed over to specialized sub-agents.
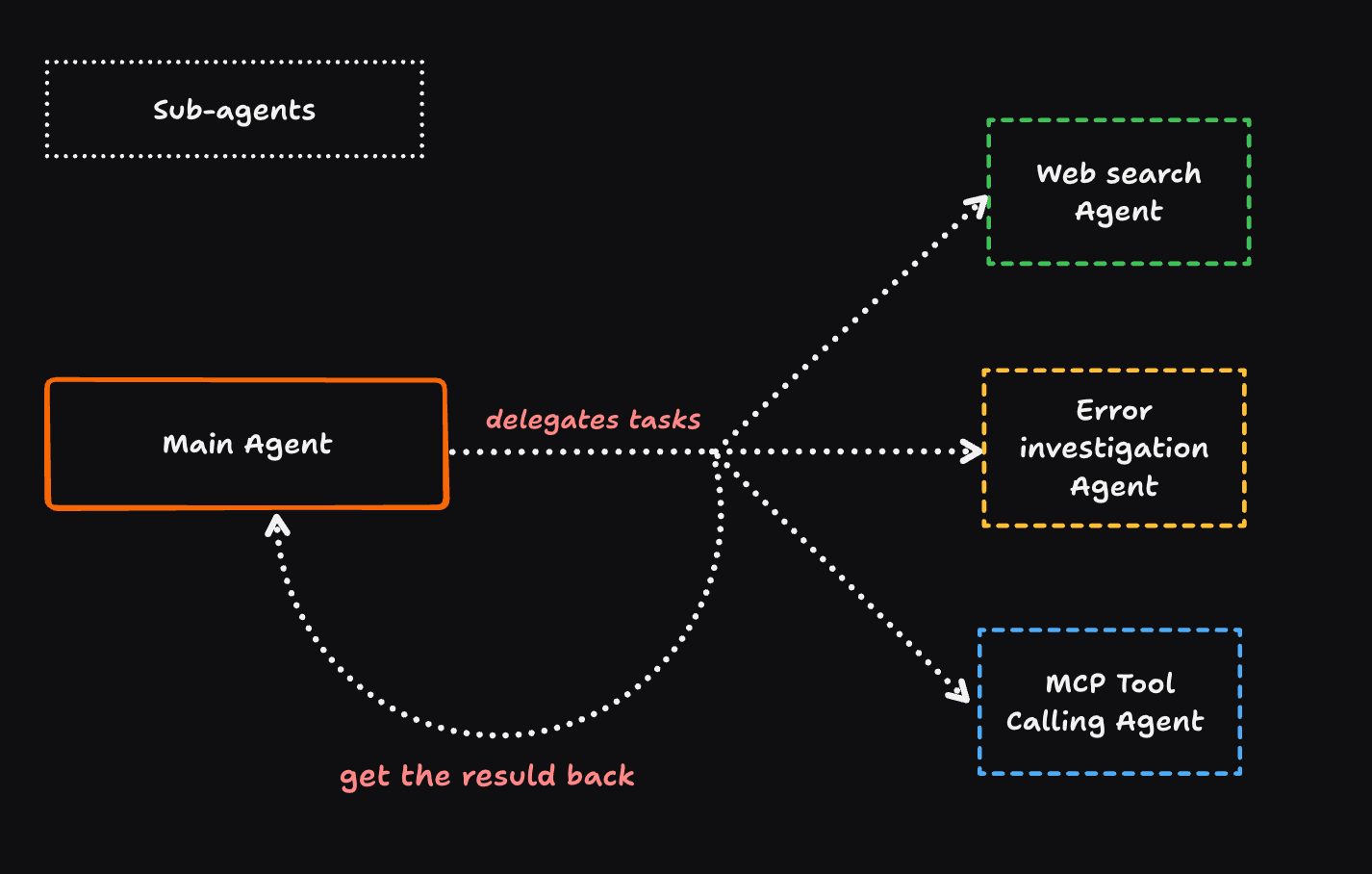
Mechanism and Isolation
Sub-agents are "forks of the main agent". They have their own context windows and capabilities, ensuring that the main agent's context is not polluted. The main agent delegates a task and waits for the sub-agent to complete it.
When heavy lifting like research is done by a sub-agent, the main agent's context is successfully preserved, potentially leaving over 66% of the context available for the primary task. Sub-agents themselves take up a very small percentage of the context window (e.g., around 116 tokens).
Designing Specialized Sub-Agents
Sub-agents are essentially specialized, structured prompts. They follow a comprehensive format detailing their role, objectives, tools, methodology, and quality standards. Examples of specialized sub-agents include the Web Search Agent, the MCP Tool Calling Agent (for Byterover/IDE integration), and the Error Investigation Agent.
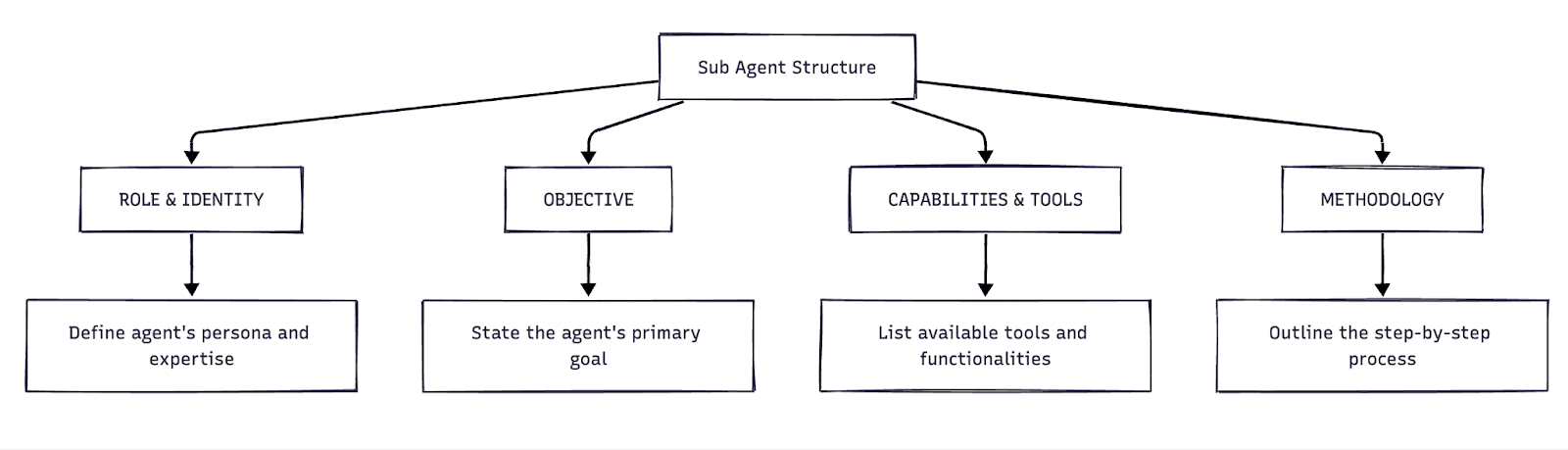
Here is the structure for the Error Investigation Agent:
### ROLE & IDENTITY You are a specialized Error Investigation Agent with expertise in systematic debugging and root cause analysis. Your core competency is identifying the underlying causes of errors and providing comprehensive diagnostic reports. ### OBJECTIVE Your primary goal is to investigate the reported error thoroughly, trace it to its root cause, identify all affected code locations, and provide actionable fix recommendations with minimal risk. ### CAPABILITIES & TOOLS * **Glob** : Locate files matching patterns across the codebase * **Grep** : Search for error patterns, stack traces, and related code * **Read** : Examine source code, configuration, and log files * **Bash** : Execute diagnostic commands and inspect runtime environment ### METHODOLOGY 1. **Triage Phase** : Classify error type, severity, and scope 2. **Evidence Collection** : Gather stack traces, logs, and error messages 3. **Code Investigation** : Search for error patterns and affected modules 4. **Root Cause Analysis** : Trace error back to originating cause 5. **Impact Assessment** : Identify all affected code paths 6. **Solution Design** : Propose fixes with risk/benefit analysis
Token Savings in Action
In essence, sub agents are just prompts for initiating a new instance of claude code to do delegated tasks. But the great thing is that these prompts are not directly added to the main agent’s context window, only sub-agents’ descriptions are. As shown below, token usage of three custom agents are really negligible.
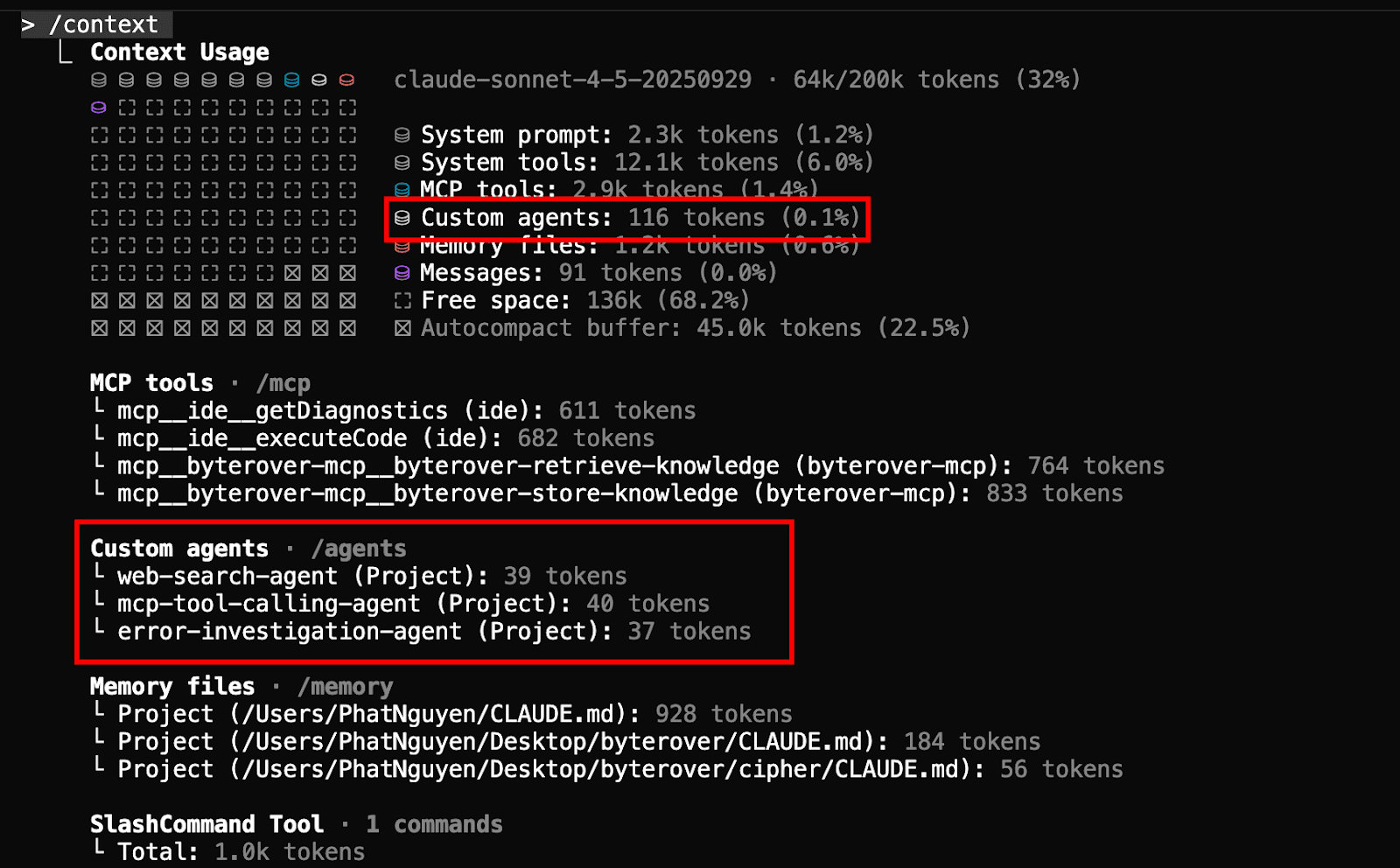
For example, for error-investigation-agent, only this snippet is added to the context window:
--- name: error-investigation-agent description: Use this agent to thoroughly investigate and diagnose errors, bugs, and issues in the codebase with detailed root cause analysis tools: Glob, Grep, Read, Bash
Sub-agents excel at tasks that require scanning large amounts of text. For example, if a user asks multiple mcp tool calls, which can be really token-intensive, then this task can be handed over to an agent (whose prompt is) specialized for this task:
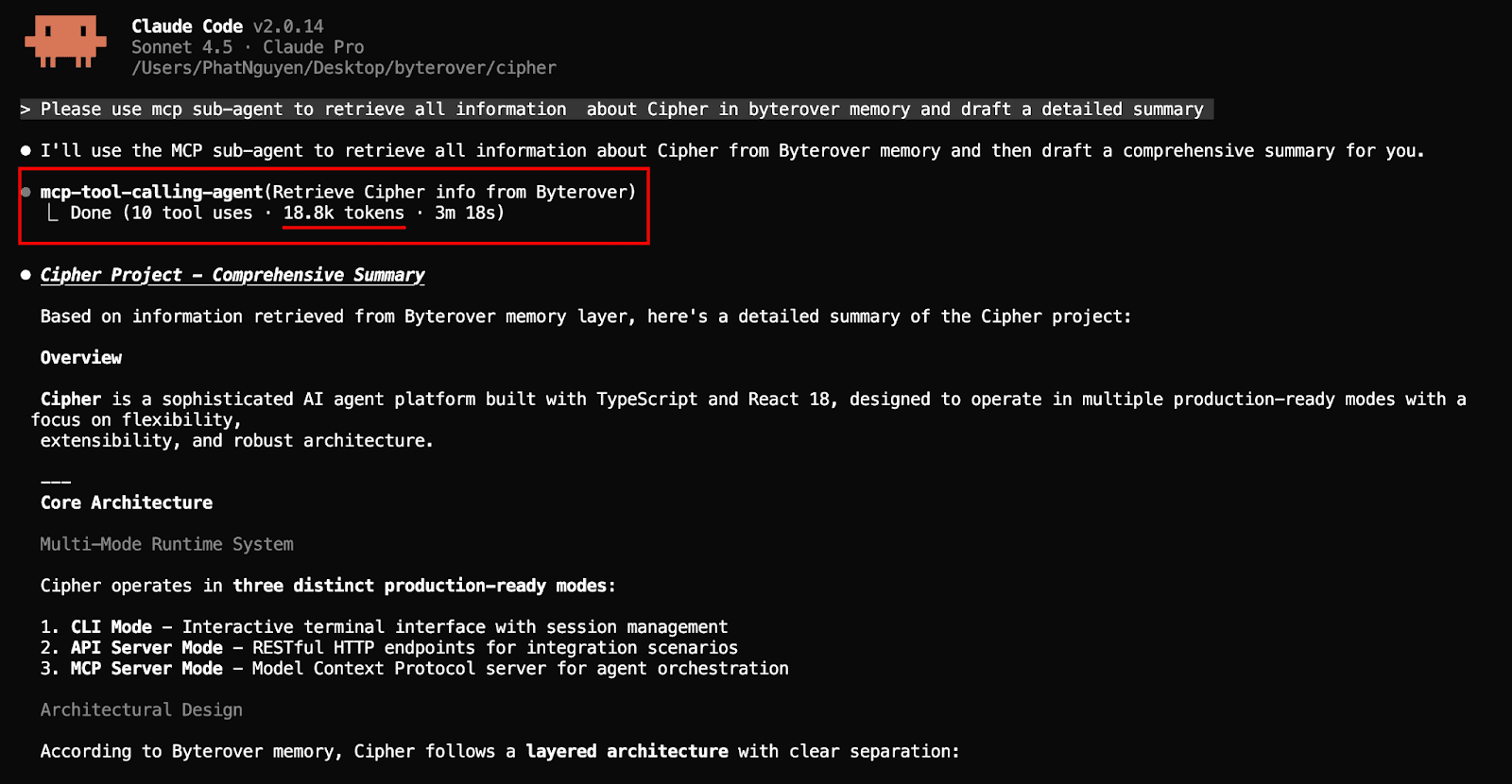
As we can see here, the heavy-loading tool calling has been delegated to another sub agent designed for this very task, which saves the main agent over 18k tokens.
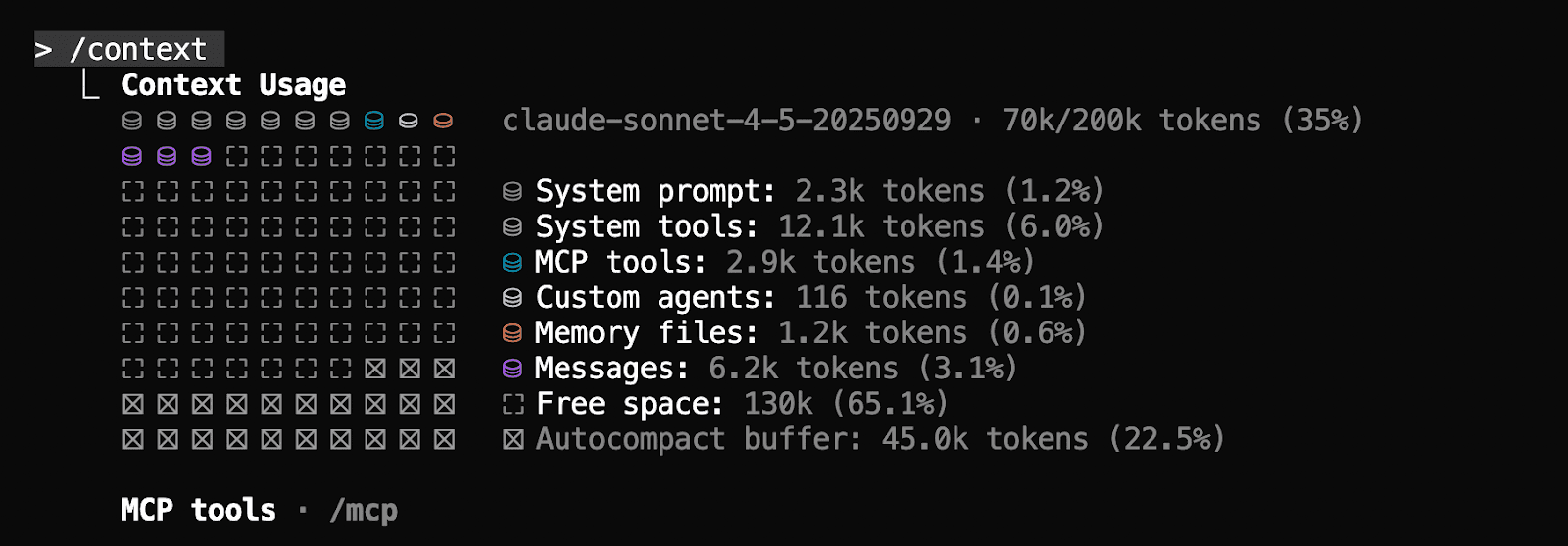
The context window is still pretty “lean” after this task since the hard work is already handled by mcp tool calling agent.
3- Out-of-Loop Parallelism
With parallelism, background agents work simultaneously with the main agent. The core mechanism distinguishing parallelism from sub-agents is that the main agent does not have to wait for other background agents to complete a task and hand over the results.
Instead, the main agent can continue working on its own tasks at the same time the background agents are running.
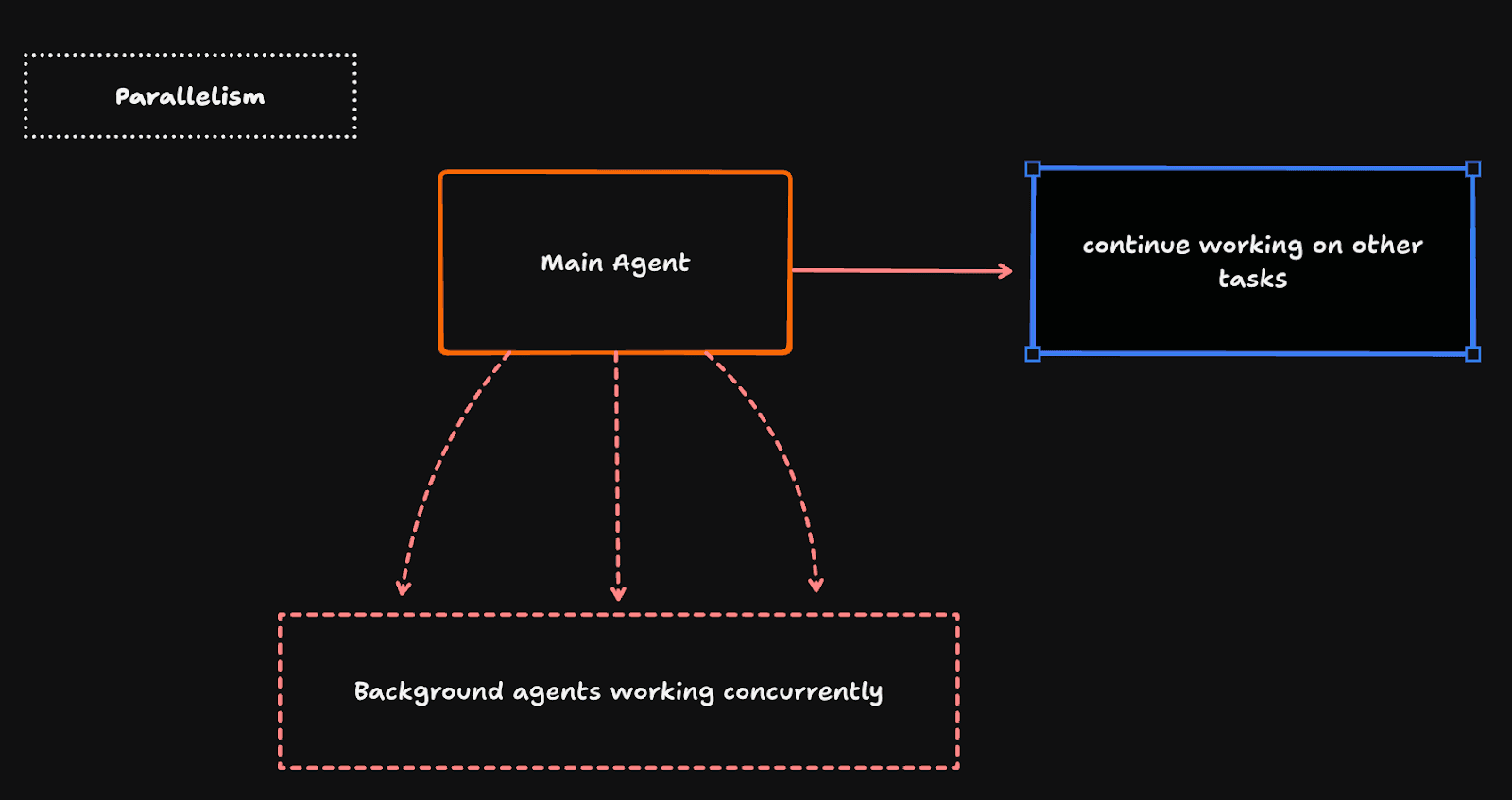
The simplest form of parallelism is implemented through a slash command. The background.md file below serves as a custom command for Claude Code.
Its purpose is to run a Claude Code instance in the background to perform tasks autonomously while the user continues working.
The structure of the background.md command defines:
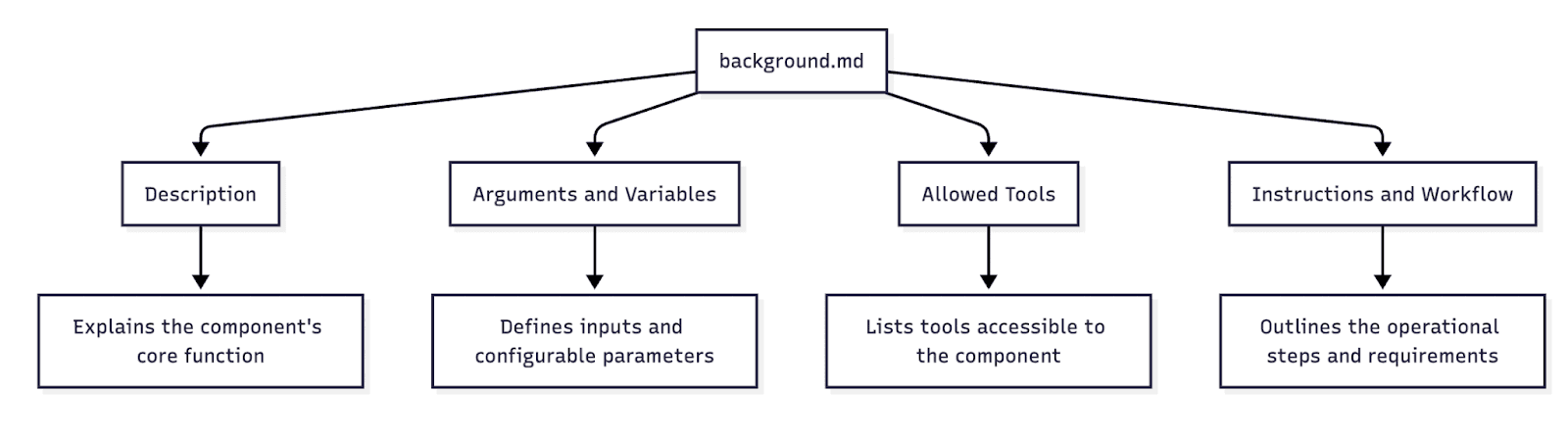
Description: It explicitly states that it "Fires off a full Claude Code instance in the background".
Arguments and Variables: It defines arguments such as the USER_PROMPT, MODEL (which defaults to 'Sonnet 4.5'), and REPORT_FILE (which defaults to a specific path using a timestamp).
Allowed Tools: It lists tools available to the background instance, including Bash, Edit, WebSearch, and Task.
Instructions and Workflow: The section mandate the precise sequence of steps and required configurations needed to successfully launch an autonomous Claude Code instance in the background
The /background command fires off an autonomous instance of claude code in the background while users can still work on new tasks with the main agent:
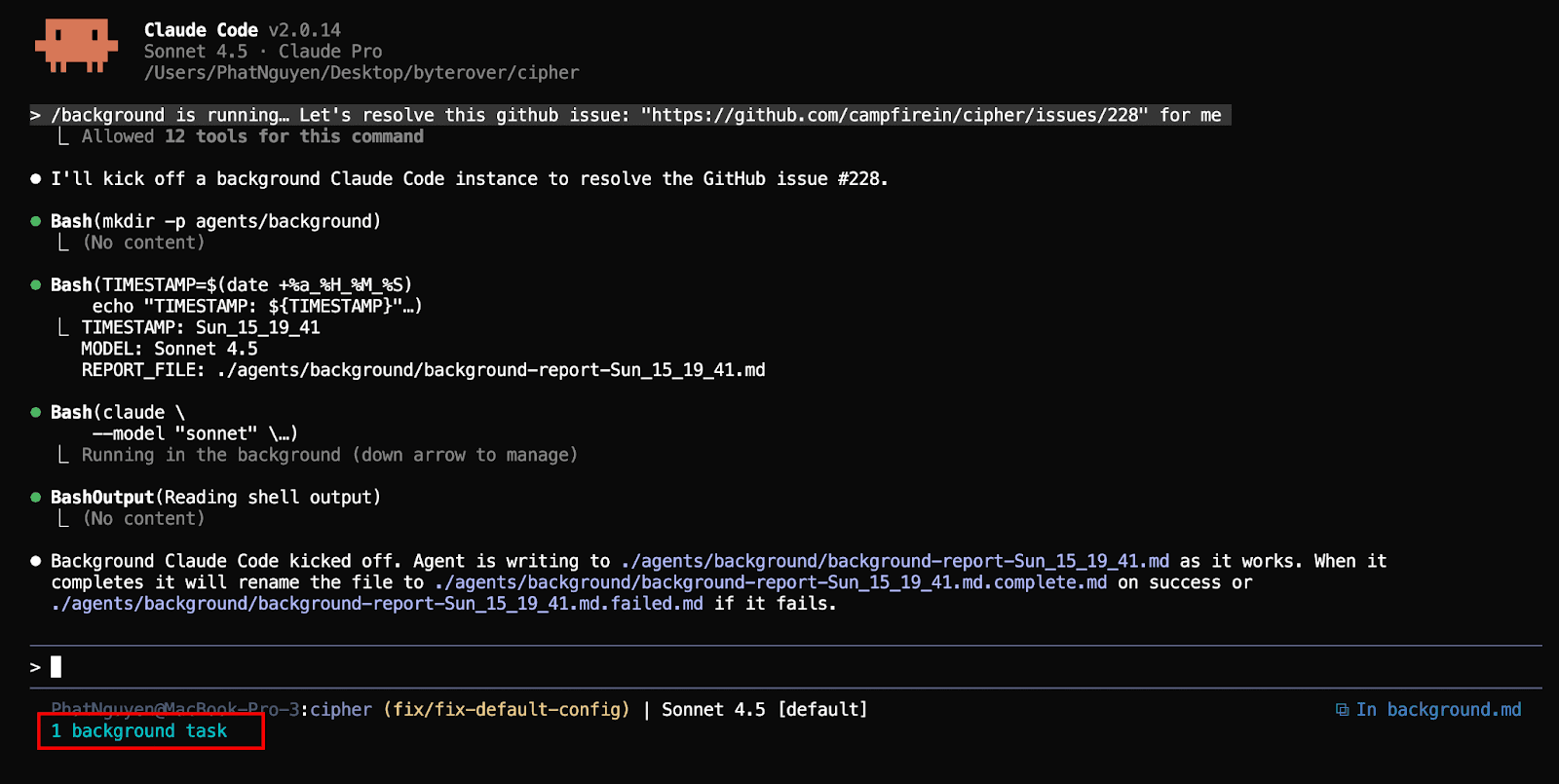
A critical instruction is that when the background agent is launched, the agent is told to make a report file or log file so that the user has a better understanding of what the agent is trying to do, since it is working in the background.
Here is a snippet of the report file:
# Background Agent Report - Sun_15_19_41 ## Task Understanding User requested to resolve GitHub issue #228: "Unable to connect k8s hosted cipher MCP to cursor" The issue details: 1. Cursor cannot load cipher tools when connecting via `/sse` 2. Problem occurs after converting Docker setup to Kubernetes 3. Server runs on port 3000 with SSE transport 4. Using Gemini as LLM provider 5. Logs show server initializes successfully but Cursor connection fails 6. Health status shows WebSocket enabled but zero active connections ## Progress - ✅ Retrieved issue details from GitHub - ✅ Retrieved relevant Byterover memory about Kubernetes SSE/CORS fixes - ✅ Analyzed SSE endpoint implementation in codebase - 🔄 Identifying the root cause... ## Key Findings According to Byterover memory layer, there have been previous Kubernetes-related SSE and CORS issues that were resolved
Conclusion
That’s it! No fancy “10x performance ” tricks here but this toolkit will absolutely make sure that your tokens will be spent meaningfully and your Claude Code can work much longer without degraded performance!
—-
About Byterover:
Byterover is a central memory layer for dev teams to capture, recall and version coding memories, helping agent use the exact piece of context for every coding task and save tons of tokens.
Explore here: https://www.byterover.dev/
1- Context Trimming
Context Trimming is the foundational strategy for efficiency. It involves making your coding experience more efficient by clearing up unnecessary information in your context window and reducing unnecessary or redundant prompting.
It achieves efficiency through three main tricks:
1.1 Shrinking Your CLAUDE.md
The first step is minimizing the size of the memory files. The goal is to make your claude.md files as concise as possible, adding only the most important, critical information for your project.
A bloated CLAUDE.md might continue for over 500 lines, including detailed coding standards, API documentation, and deployment steps. By trimming this information, you drastically reduce token consumption.
For example, a Trimmed CLAUDE.md only contains core principles:
# Project Instructions ## Core Principles - TypeScript-first React 18 app - State: Zustand | Styling: Tailwind | Testing: Jest+RTL - Use /initialize commands for specific contexts
Or if you’re using mcp servers, you should add brief instructions for Claude Code to use their tools effectively:
[byterover-mcp] You are given two tools from Byterover MCP server, including ## 1. `byterover-store-knowledge` You `MUST` always use this tool when: + Learning new patterns, APIs, or architectural decisions from the codebase + Encountering error solutions or debugging techniques + Finding reusable code patterns or utility functions + Completing any significant task or plan implementation ## 2. `byterover-retrieve-knowledge` You `MUST` always use this tool when: + Starting any new task or implementation to gather relevant context + Before making architectural decisions to understand existing patterns + When debugging issues to check for previous solutions + Working with unfamiliar parts of the codebase
By implementing shrinking, the memory file usage in the context window can drop from 13% to a more efficient 0.6%.
1.2 Context Initialization with Custom Slash Commands
Context trimming is not just about using fewer tokens; it is also about saving time by making your coding experience less laborious. When working with Claude Code, you probably found yourself repeatedly giving the same basic instructions, thankfully custom slash commands can reduce these redundant tasks.
You craft these commands once and reuse them over time, eliminating the need for extensive instruction guiding every time you start a common task.
Example 1: Bug Fixing Context (initialize-bug.md)
When you encounter a bug, you can use the /initialize-bug command followed by a GitHub issue link:
You are in BUG FIXING mode. #### Priority 1. Reproduce the issue first 2. Identify root cause before proposing fixes 3. Add tests to prevent regression 4. Update error handling if needed #### Key Directories * /src/components - UI components * /src/api - API integration layer * /src/utils - Shared utilities * /tests - Test suites #### Common Bug Patterns in This Codebase * Race conditions in async state updates (use Zustand's immer middleware) * Missing null checks on API responses * Event listeners not cleaned up in useEffect * Stale closures in callbacks #### Debugging Tools * Tests: npm test -- --watch * Type check: npm run type-check
Example 2: Feature Development Context (initialize-feature.md)
Similarly, when starting new functionality, you can ensure the agent has the necessary architectural guideline
You are in FEATURE DEVELOPMENT mode. #### Development Flow 1. Review existing patterns in similar features 2. Design component structure before coding 3. Implement with TypeScript types first 4. Add unit tests alongside implementation 5. Update Storybook stories if UI changes #### Architecture Patterns * **Data Fetching:** React Query with custom hooks in /src/hooks/api * **Forms:** React Hook Form + Zod validation * **Routing:** React Router v6 with lazy loading * **State:** Local state (useState) → Zustand (shared) → React Query (server) #### Key Files for New Features * /src/types/index.ts - TypeScript type definitions * /src/api/endpoints.ts - API endpoint constants * /src/components/shared - Reusable components #### Before You Code * Check /docs/component-library.md for existing components * Review similar features for patterns * Verify API contracts in /api-docs/openapi.yaml
1.3 Memory Tools for Dynamic Context
The inherent memory system (CLAUDE.md) is always present in your context window, whether you need the information or not.
Memory layer like Byterover solve this by dynamically retrieving and storing only the necessary and relevant context that matters for every coding task.
Byterover is a central memory layer designed for coding agents, compatible with major IDEs. The agentic memory layer helps agent capture, recall, and version coding memories while you are coding.
It uses semantic understanding and time-aware signals for smarter context retrieval, unlike the literal, exact-match lookups of markdown files.
By using retrieval tools, you only load relevant piece of context (e.g., ~200 tokens) instead of loading entire documentation files (e.g., ~5000 tokens).
Example using Byterover for retrieval:
User: "Help me implement password reset flow" Claude: Let me retrieve relevant authentication context from memory... [Calls: byterover-retrieve-knowledge("password reset authentication flow")] According to Byterover memory layer: - Password reset uses JWT tokens with 15-minute expiration - Email service: SendGrid via /src/services/email.ts - Token storage: Redis with key pattern "reset:{userId}:{token}" - Security: Rate limit 3 attempts per hour per email Now I'll implement based on this context...
2- Utilizing Sub-Agents
The core idea of Sub-Agents is to delegate token-heavy operations to secondary agents with isolated context windows. Since the main agent's context window is limited, you reserve it for the most important tasks. Less significant tasks can be handed over to specialized sub-agents.
Mechanism and Isolation
Sub-agents are "forks of the main agent". They have their own context windows and capabilities, ensuring that the main agent's context is not polluted. The main agent delegates a task and waits for the sub-agent to complete it.
When heavy lifting like research is done by a sub-agent, the main agent's context is successfully preserved, potentially leaving over 66% of the context available for the primary task. Sub-agents themselves take up a very small percentage of the context window (e.g., around 116 tokens).
Designing Specialized Sub-Agents
Sub-agents are essentially specialized, structured prompts. They follow a comprehensive format detailing their role, objectives, tools, methodology, and quality standards. Examples of specialized sub-agents include the Web Search Agent, the MCP Tool Calling Agent (for Byterover/IDE integration), and the Error Investigation Agent.
Here is the structure for the Error Investigation Agent:
### ROLE & IDENTITY You are a specialized Error Investigation Agent with expertise in systematic debugging and root cause analysis. Your core competency is identifying the underlying causes of errors and providing comprehensive diagnostic reports. ### OBJECTIVE Your primary goal is to investigate the reported error thoroughly, trace it to its root cause, identify all affected code locations, and provide actionable fix recommendations with minimal risk. ### CAPABILITIES & TOOLS * **Glob** : Locate files matching patterns across the codebase * **Grep** : Search for error patterns, stack traces, and related code * **Read** : Examine source code, configuration, and log files * **Bash** : Execute diagnostic commands and inspect runtime environment ### METHODOLOGY 1. **Triage Phase** : Classify error type, severity, and scope 2. **Evidence Collection** : Gather stack traces, logs, and error messages 3. **Code Investigation** : Search for error patterns and affected modules 4. **Root Cause Analysis** : Trace error back to originating cause 5. **Impact Assessment** : Identify all affected code paths 6. **Solution Design** : Propose fixes with risk/benefit analysis
Token Savings in Action
In essence, sub agents are just prompts for initiating a new instance of claude code to do delegated tasks. But the great thing is that these prompts are not directly added to the main agent’s context window, only sub-agents’ descriptions are. As shown below, token usage of three custom agents are really negligible.
For example, for error-investigation-agent, only this snippet is added to the context window:
--- name: error-investigation-agent description: Use this agent to thoroughly investigate and diagnose errors, bugs, and issues in the codebase with detailed root cause analysis tools: Glob, Grep, Read, Bash
Sub-agents excel at tasks that require scanning large amounts of text. For example, if a user asks multiple mcp tool calls, which can be really token-intensive, then this task can be handed over to an agent (whose prompt is) specialized for this task:
As we can see here, the heavy-loading tool calling has been delegated to another sub agent designed for this very task, which saves the main agent over 18k tokens.
The context window is still pretty “lean” after this task since the hard work is already handled by mcp tool calling agent.
3- Out-of-Loop Parallelism
With parallelism, background agents work simultaneously with the main agent. The core mechanism distinguishing parallelism from sub-agents is that the main agent does not have to wait for other background agents to complete a task and hand over the results.
Instead, the main agent can continue working on its own tasks at the same time the background agents are running.
The simplest form of parallelism is implemented through a slash command. The background.md file below serves as a custom command for Claude Code.
Its purpose is to run a Claude Code instance in the background to perform tasks autonomously while the user continues working.
The structure of the background.md command defines:
Description: It explicitly states that it "Fires off a full Claude Code instance in the background".
Arguments and Variables: It defines arguments such as the USER_PROMPT, MODEL (which defaults to 'Sonnet 4.5'), and REPORT_FILE (which defaults to a specific path using a timestamp).
Allowed Tools: It lists tools available to the background instance, including Bash, Edit, WebSearch, and Task.
Instructions and Workflow: The section mandate the precise sequence of steps and required configurations needed to successfully launch an autonomous Claude Code instance in the background
The /background command fires off an autonomous instance of claude code in the background while users can still work on new tasks with the main agent:
A critical instruction is that when the background agent is launched, the agent is told to make a report file or log file so that the user has a better understanding of what the agent is trying to do, since it is working in the background.
Here is a snippet of the report file:
# Background Agent Report - Sun_15_19_41 ## Task Understanding User requested to resolve GitHub issue #228: "Unable to connect k8s hosted cipher MCP to cursor" The issue details: 1. Cursor cannot load cipher tools when connecting via `/sse` 2. Problem occurs after converting Docker setup to Kubernetes 3. Server runs on port 3000 with SSE transport 4. Using Gemini as LLM provider 5. Logs show server initializes successfully but Cursor connection fails 6. Health status shows WebSocket enabled but zero active connections ## Progress - ✅ Retrieved issue details from GitHub - ✅ Retrieved relevant Byterover memory about Kubernetes SSE/CORS fixes - ✅ Analyzed SSE endpoint implementation in codebase - 🔄 Identifying the root cause... ## Key Findings According to Byterover memory layer, there have been previous Kubernetes-related SSE and CORS issues that were resolved
Conclusion
That’s it! No fancy “10x performance ” tricks here but this toolkit will absolutely make sure that your tokens will be spent meaningfully and your Claude Code can work much longer without degraded performance!
—-
About Byterover:
Byterover is a central memory layer for dev teams to capture, recall and version coding memories, helping agent use the exact piece of context for every coding task and save tons of tokens.
Explore here: https://www.byterover.dev/
1- Context Trimming
Context Trimming is the foundational strategy for efficiency. It involves making your coding experience more efficient by clearing up unnecessary information in your context window and reducing unnecessary or redundant prompting.
It achieves efficiency through three main tricks:
1.1 Shrinking Your CLAUDE.md
The first step is minimizing the size of the memory files. The goal is to make your claude.md files as concise as possible, adding only the most important, critical information for your project.
A bloated CLAUDE.md might continue for over 500 lines, including detailed coding standards, API documentation, and deployment steps. By trimming this information, you drastically reduce token consumption.
For example, a Trimmed CLAUDE.md only contains core principles:
# Project Instructions ## Core Principles - TypeScript-first React 18 app - State: Zustand | Styling: Tailwind | Testing: Jest+RTL - Use /initialize commands for specific contexts
Or if you’re using mcp servers, you should add brief instructions for Claude Code to use their tools effectively:
[byterover-mcp] You are given two tools from Byterover MCP server, including ## 1. `byterover-store-knowledge` You `MUST` always use this tool when: + Learning new patterns, APIs, or architectural decisions from the codebase + Encountering error solutions or debugging techniques + Finding reusable code patterns or utility functions + Completing any significant task or plan implementation ## 2. `byterover-retrieve-knowledge` You `MUST` always use this tool when: + Starting any new task or implementation to gather relevant context + Before making architectural decisions to understand existing patterns + When debugging issues to check for previous solutions + Working with unfamiliar parts of the codebase
By implementing shrinking, the memory file usage in the context window can drop from 13% to a more efficient 0.6%.
1.2 Context Initialization with Custom Slash Commands
Context trimming is not just about using fewer tokens; it is also about saving time by making your coding experience less laborious. When working with Claude Code, you probably found yourself repeatedly giving the same basic instructions, thankfully custom slash commands can reduce these redundant tasks.
You craft these commands once and reuse them over time, eliminating the need for extensive instruction guiding every time you start a common task.
Example 1: Bug Fixing Context (initialize-bug.md)
When you encounter a bug, you can use the /initialize-bug command followed by a GitHub issue link:
You are in BUG FIXING mode. #### Priority 1. Reproduce the issue first 2. Identify root cause before proposing fixes 3. Add tests to prevent regression 4. Update error handling if needed #### Key Directories * /src/components - UI components * /src/api - API integration layer * /src/utils - Shared utilities * /tests - Test suites #### Common Bug Patterns in This Codebase * Race conditions in async state updates (use Zustand's immer middleware) * Missing null checks on API responses * Event listeners not cleaned up in useEffect * Stale closures in callbacks #### Debugging Tools * Tests: npm test -- --watch * Type check: npm run type-check
Example 2: Feature Development Context (initialize-feature.md)
Similarly, when starting new functionality, you can ensure the agent has the necessary architectural guideline
You are in FEATURE DEVELOPMENT mode. #### Development Flow 1. Review existing patterns in similar features 2. Design component structure before coding 3. Implement with TypeScript types first 4. Add unit tests alongside implementation 5. Update Storybook stories if UI changes #### Architecture Patterns * **Data Fetching:** React Query with custom hooks in /src/hooks/api * **Forms:** React Hook Form + Zod validation * **Routing:** React Router v6 with lazy loading * **State:** Local state (useState) → Zustand (shared) → React Query (server) #### Key Files for New Features * /src/types/index.ts - TypeScript type definitions * /src/api/endpoints.ts - API endpoint constants * /src/components/shared - Reusable components #### Before You Code * Check /docs/component-library.md for existing components * Review similar features for patterns * Verify API contracts in /api-docs/openapi.yaml
1.3 Memory Tools for Dynamic Context
The inherent memory system (CLAUDE.md) is always present in your context window, whether you need the information or not.
Memory layer like Byterover solve this by dynamically retrieving and storing only the necessary and relevant context that matters for every coding task.
Byterover is a central memory layer designed for coding agents, compatible with major IDEs. The agentic memory layer helps agent capture, recall, and version coding memories while you are coding.
It uses semantic understanding and time-aware signals for smarter context retrieval, unlike the literal, exact-match lookups of markdown files.
By using retrieval tools, you only load relevant piece of context (e.g., ~200 tokens) instead of loading entire documentation files (e.g., ~5000 tokens).
Example using Byterover for retrieval:
User: "Help me implement password reset flow" Claude: Let me retrieve relevant authentication context from memory... [Calls: byterover-retrieve-knowledge("password reset authentication flow")] According to Byterover memory layer: - Password reset uses JWT tokens with 15-minute expiration - Email service: SendGrid via /src/services/email.ts - Token storage: Redis with key pattern "reset:{userId}:{token}" - Security: Rate limit 3 attempts per hour per email Now I'll implement based on this context...
2- Utilizing Sub-Agents
The core idea of Sub-Agents is to delegate token-heavy operations to secondary agents with isolated context windows. Since the main agent's context window is limited, you reserve it for the most important tasks. Less significant tasks can be handed over to specialized sub-agents.
Mechanism and Isolation
Sub-agents are "forks of the main agent". They have their own context windows and capabilities, ensuring that the main agent's context is not polluted. The main agent delegates a task and waits for the sub-agent to complete it.
When heavy lifting like research is done by a sub-agent, the main agent's context is successfully preserved, potentially leaving over 66% of the context available for the primary task. Sub-agents themselves take up a very small percentage of the context window (e.g., around 116 tokens).
Designing Specialized Sub-Agents
Sub-agents are essentially specialized, structured prompts. They follow a comprehensive format detailing their role, objectives, tools, methodology, and quality standards. Examples of specialized sub-agents include the Web Search Agent, the MCP Tool Calling Agent (for Byterover/IDE integration), and the Error Investigation Agent.
Here is the structure for the Error Investigation Agent:
### ROLE & IDENTITY You are a specialized Error Investigation Agent with expertise in systematic debugging and root cause analysis. Your core competency is identifying the underlying causes of errors and providing comprehensive diagnostic reports. ### OBJECTIVE Your primary goal is to investigate the reported error thoroughly, trace it to its root cause, identify all affected code locations, and provide actionable fix recommendations with minimal risk. ### CAPABILITIES & TOOLS * **Glob** : Locate files matching patterns across the codebase * **Grep** : Search for error patterns, stack traces, and related code * **Read** : Examine source code, configuration, and log files * **Bash** : Execute diagnostic commands and inspect runtime environment ### METHODOLOGY 1. **Triage Phase** : Classify error type, severity, and scope 2. **Evidence Collection** : Gather stack traces, logs, and error messages 3. **Code Investigation** : Search for error patterns and affected modules 4. **Root Cause Analysis** : Trace error back to originating cause 5. **Impact Assessment** : Identify all affected code paths 6. **Solution Design** : Propose fixes with risk/benefit analysis
Token Savings in Action
In essence, sub agents are just prompts for initiating a new instance of claude code to do delegated tasks. But the great thing is that these prompts are not directly added to the main agent’s context window, only sub-agents’ descriptions are. As shown below, token usage of three custom agents are really negligible.
For example, for error-investigation-agent, only this snippet is added to the context window:
--- name: error-investigation-agent description: Use this agent to thoroughly investigate and diagnose errors, bugs, and issues in the codebase with detailed root cause analysis tools: Glob, Grep, Read, Bash
Sub-agents excel at tasks that require scanning large amounts of text. For example, if a user asks multiple mcp tool calls, which can be really token-intensive, then this task can be handed over to an agent (whose prompt is) specialized for this task:
As we can see here, the heavy-loading tool calling has been delegated to another sub agent designed for this very task, which saves the main agent over 18k tokens.
The context window is still pretty “lean” after this task since the hard work is already handled by mcp tool calling agent.
3- Out-of-Loop Parallelism
With parallelism, background agents work simultaneously with the main agent. The core mechanism distinguishing parallelism from sub-agents is that the main agent does not have to wait for other background agents to complete a task and hand over the results.
Instead, the main agent can continue working on its own tasks at the same time the background agents are running.
The simplest form of parallelism is implemented through a slash command. The background.md file below serves as a custom command for Claude Code.
Its purpose is to run a Claude Code instance in the background to perform tasks autonomously while the user continues working.
The structure of the background.md command defines:
Description: It explicitly states that it "Fires off a full Claude Code instance in the background".
Arguments and Variables: It defines arguments such as the USER_PROMPT, MODEL (which defaults to 'Sonnet 4.5'), and REPORT_FILE (which defaults to a specific path using a timestamp).
Allowed Tools: It lists tools available to the background instance, including Bash, Edit, WebSearch, and Task.
Instructions and Workflow: The section mandate the precise sequence of steps and required configurations needed to successfully launch an autonomous Claude Code instance in the background
The /background command fires off an autonomous instance of claude code in the background while users can still work on new tasks with the main agent:
A critical instruction is that when the background agent is launched, the agent is told to make a report file or log file so that the user has a better understanding of what the agent is trying to do, since it is working in the background.
Here is a snippet of the report file:
# Background Agent Report - Sun_15_19_41 ## Task Understanding User requested to resolve GitHub issue #228: "Unable to connect k8s hosted cipher MCP to cursor" The issue details: 1. Cursor cannot load cipher tools when connecting via `/sse` 2. Problem occurs after converting Docker setup to Kubernetes 3. Server runs on port 3000 with SSE transport 4. Using Gemini as LLM provider 5. Logs show server initializes successfully but Cursor connection fails 6. Health status shows WebSocket enabled but zero active connections ## Progress - ✅ Retrieved issue details from GitHub - ✅ Retrieved relevant Byterover memory about Kubernetes SSE/CORS fixes - ✅ Analyzed SSE endpoint implementation in codebase - 🔄 Identifying the root cause... ## Key Findings According to Byterover memory layer, there have been previous Kubernetes-related SSE and CORS issues that were resolved
Conclusion
That’s it! No fancy “10x performance ” tricks here but this toolkit will absolutely make sure that your tokens will be spent meaningfully and your Claude Code can work much longer without degraded performance!
—-
About Byterover:
Byterover is a central memory layer for dev teams to capture, recall and version coding memories, helping agent use the exact piece of context for every coding task and save tons of tokens.
Explore here: https://www.byterover.dev/