Product Release
Benchmarking AI agent memory: ByteRover 2.0 Scores 92.2% and Rewrites the LoCoMo Leaderboard
ByteRover CLI 2.0 comes with fundamentally better architecture. CLI 2.0 does not just improve on ByteRover 1.x - ByteRover CLI 2.0 outperforms every major memory system to claim the top spot on the industry's toughest long-term memory benchmark.

1. TL;DR
ByteRover 2.0 achieves 92.2% overall accuracy on the LoCoMo benchmark - matching or beating every major AI memory system.
94.4% on Temporal reasoning - best in class, ahead of Hindsight (83.8%) and Memobase (85.1%).
95.4% on Single-hop recall - surpassing every competitor.
85.1% on Multi-hop - outperforming Hindsight (70.8%) by 14.3 points.
77.2% on Open Domain - equivalent to Memobase (77.2%) and ahead of Mem0 (72.9%).
Built on a new Context Tree architecture and Retrieval System that retrieves smarter, not harder.
Still got 90.9% overall with Gemini-3-flash (whole benchmark process) - proving the architecture carries the weight, not the model.
2. The Problem
Your AI Forgets Everything
Think about the people you trust most - your doctor, your financial advisor, a close colleague. What makes them effective isn't just their expertise. It's that they remember. They remember what you told them last month, what worked before, what didn't, and what matters to you.
Now think about your AI assistant. Every new conversation starts from scratch. The preferences you shared last week? Gone. The complex decision you worked through over multiple sessions? Forgotten. You're stuck in a Groundhog Day loop - repeating yourself, re-explaining context, re-establishing trust.
This isn't a minor UX annoyance - it's a fundamental limitation. Without long-term memory, AI can't truly personalize, can't learn from past interactions, and can't handle tasks that unfold over days, weeks, or months. Customer support agents ask the same diagnostic questions on every call. Coding assistants forget the architecture decisions you made yesterday. Health assistants lose track of your symptoms over time.
The industry is racing to fix this
By 2025, every major AI platform - OpenAI, Anthropic, Google, Microsoft - has shipped some form of memory. But as even Mem0's own research acknowledges, extending context windows "merely delay rather than solve the fundamental limitation" - users jump between topics, burying critical information among irrelevant content.
This gap has spawned a wave of specialized memory systems, each taking a fundamentally different architectural approach:
Mem0 extracts salient memories from conversation pairs and applies discrete operations (add, update, delete) to maintain a memory store - with an enhanced graph variant that captures entity relationships.
Zep builds temporal knowledge graphs from conversations, encoding entities, relationships, and timestamps for time-aware retrieval.
Hindsight organizes memory into four logical networks (world facts, experiences, opinions, summaries) and implements a retain-recall-reflect pipeline with 4-way parallel retrieval.
Each claims to be the best. But claims are easy. The real question is: when you put them all through the same test, who actually remembers?
That's exactly what we did. We ran ByteRover 2.0 through the LoCoMo benchmark - the industry's most widely used test for long-term conversational memory - using our toughest competitor's own evaluation rules.
The results surprised even us.
3. What is LoCoMo?
LoCoMo dataset
Before we show you the numbers, let's talk about the test.
LoCoMo (Long-term Conversation Memory) is a benchmark created by researchers at UNC Chapel Hill, USC, and Snap Research, published at ACL 2024 - one of the top venues in natural language processing. It has since become the most widely adopted benchmark for evaluating AI memory systems, used by Mem0, Zep, Hindsight, Memobase, and others to validate their claims.
The setup
Imagine two people who've been chatting for months - about their jobs, relationships, hobbies, health, travel plans. These conversations span up to 35 sessions, averaging 600 turns and ~16,000 tokens per dialogue. Topics shift naturally. Details pile up. Some things change over time.
Now, quiz the AI on what was said.
LoCoMo does exactly this: 10 long-form conversations, 272 sessions, and 1,982 questions — each designed to test a different kind of memory.
The five question types
Category | What it tests | Example |
|---|---|---|
Single-hop (841 questions) | Simple factual recall from one session | "What is Alice's new job title?" |
Multi-hop (282 questions) | Connecting information across multiple sessions | "Did Alice and Bob ever discuss the same restaurant?" |
Temporal (321 questions) | Understanding time — what happened before, after, or when | "What did Alice say about her job before she got promoted?" |
Open Domain (92 questions) | Inference and commonsense reasoning beyond explicit text | "Based on their conversations, what kind of person is Alice?" |
Adversarial (446 questions) | Trick questions — the correct answer is often "this was never discussed" | "What did Alice say about her trip to Mars?" |
Why it matters
When the LoCoMo authors tested leading LLMs directly on a 4K context window, GPT-4, GPT-3.5, Llama-2, Mistral, even the best (GPT-4) scored just 32.1 F1, while humans scored 87.9 F1. That's a 56-point gap. Even GPT-3.5 with 16K context only reached 37.8 F1. LLMs alone, regardless of context length, can't do this. You need a memory system.
A note on methodology
Most memory builders on the market - Hindsight, Mem0, Zep, Memobase - report results on 4 categories, excluding adversarial. The primary metric is LLM-as-Judge accuracy: an LLM evaluates whether the system's answer is semantically correct given the ground truth. This has become the standard evaluation method across the field.
4. Experiment Setup
How We Evaluated ByteRover 2.0
Benchmarks are only meaningful when the rules are clear. Here's exactly how we ran ours.
Evaluation methodology
We adopted Hindsight's evaluation prompt - both for the LLM judge and the answer justifier. Hindsight currently holds the strongest independently-verified results on LoCoMo, so using their exact methodology ensures a direct, apples-to-apples comparison. No custom prompts, no scoring advantages.
Configuration
Component | Detail |
|---|---|
Evaluation prompt | Hindsight's LLM-as-Judge & Justifier prompt |
Curate/Query model | Gemini 3 Flash |
Justifier model | Gemini 3 Flash/Pro |
Judge model | Gemini 3-Flash |
Query format | Question only — no conversation ID or session hint |
Corpus | 272 sessions across 10 conversations |
Total queries | 1,982 |
The three-stage pipeline
Curate - Gemini 3 Flash processes each conversation session and organizes it into ByteRover's Context Tree
Retrieve - For each question, ByteRover retrieves relevant context with Gemini 3 Flash
Justify - Gemini 3 Flash/Pro synthesizes an answer using Hindsight's justifier prompt
Judge - Gemini 3 Flash evaluates whether the answer is correct against the ground truth, using Hindsight's judge prompt
What makes this a hard test
Two design choices make our evaluation deliberately harder than most:
1. No conversation hints: Many benchmarks pass the conversation ID alongside the question - essentially telling the system where to look. We don't. ByteRover receives only the raw question and must retrieve the relevant context from all 272 sessions on its own. This tests true retrieval quality, not pattern matching.
2. Independent judge: In Run 2 we use a separate, lighter model (Gemini 3 Flash) as the judge - distinct from justification model. This prevents the system from grading its own homework.
5. Results - The Comparison Table
Results
We ran two experiments, one with a lightweight model across the board, and one with a stronger curation and justification model. Both used Hindsight's exact evaluation prompt.
Experiment Configurations
Run 1 | Run 2 (Best) | |
|---|---|---|
Curate model | Gemini 3 Flash | Gemini 3 Flash |
Justifier model | Gemini 3 Flash | Gemini 3 Pro |
Judge model | Gemini 3 Flash | Gemini 3 Flash |
Overall accuracy | 90.9% | 92.2% |
Overall Leaderboard
System | Single-Hop | Multi-Hop | Open Domain | Temporal | Overall |
|---|---|---|---|---|---|
ByteRover 2.0 (Run 2 - best) | 95.4% | 85.1% | 77.2.1% | 94.4% | 92.2% |
ByteRover 2.0 (Run 1) | 93.9% | 82.6% | 77.2.0% | 94.4% | 90.9% |
Hindsight (Gemini-3) | 86.2% | 70.8% | 95.1% | 83.8% | 89.6% |
Memobase v0.0.37 | 70.9% | 46.9% | 77.2% | 85.1% | 75.8% |
Zep | 74.1% | 66.0% | 67.7% | 79.8% | 75.1% |
Mem0-Graph | 65.7% | 47.2% | 75.7% | 58.1% | 68.4% |
Mem0 | 67.1% | 51.2% | 72.9% | 55.5% | 66.9% |
OpenAI Memory | 63.8% | 42.9% | 62.3% | 21.7% | 52.9% |
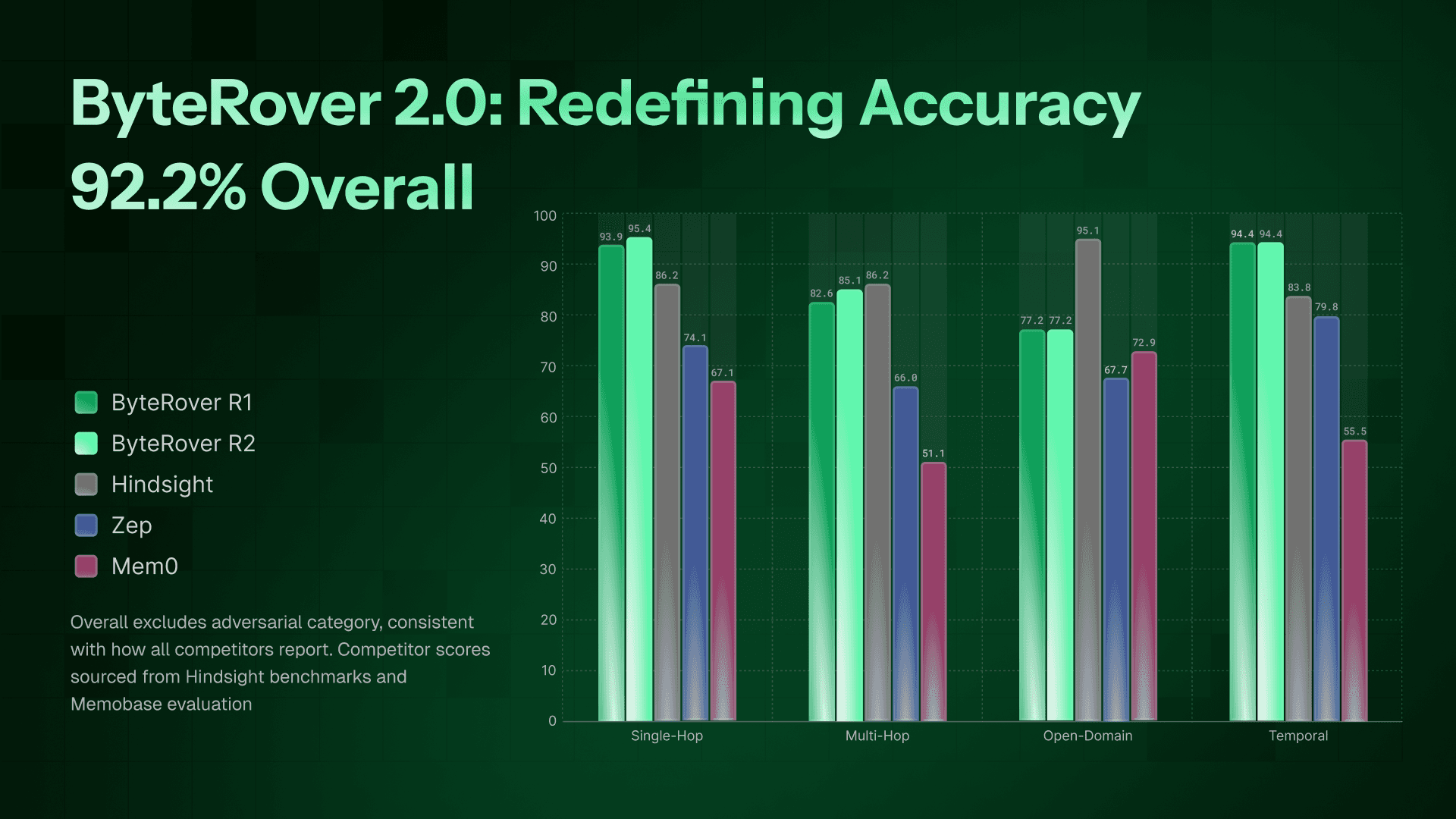
Overall excludes adversarial category, consistent with how all competitors report. Competitor scores sourced from Hindsight benchmarks and Memobase evaluation.
What the two experiments tell us
Even with the lightweight Gemini 3 Flash across all stages, ByteRover 2.0 scores 90.9% - already matching Hindsight's best result (89.6%). Upgrading to Gemini 3 Pro for justification pushes the score to 92.2%, a +2.6% leap over the previous best.
This confirms that ByteRover's Context Tree architecture & Retrieval system are the primary driver - not the model. A stronger model amplifies the results, but even a budget model matches the top of the leaderboard.
The gap at a glance (Run 2 - best)
vs. Competitor | ByteRover Advantage |
|---|---|
vs. Hindsight (next best verified) | +2.6% overall |
vs. Memobase | +16.4% overall |
vs. Zep | +17.1% overall |
vs. Mem0 | +25.3% overall |
vs. OpenAI Memory | +39.3% overall |

6. Analysis
What the Numbers Tell Us
The leaderboard tells you who won. This section explains why.
Temporal reasoning (94.4%) - Best in class by a wide margin
Temporal questions are among the hardest in LoCoMo. They require understanding when things happened, in what order, and how facts changed over time "What did Alice say about her job before she got promoted?" or "How long after moving to New York did Bob start his new role?"
Most memory systems struggle here because they store facts without preserving chronological structure. Mem0 scores 55.5%. Zep, despite building temporal knowledge graphs specifically for this, reaches 79.8%. Hindsight gets to 83.8%.
ByteRover hits 94.4%. The Context Tree naturally preserves session order and timestamps during curation, so temporal relationships are baked into the structure - not reconstructed at query time.
Single-hop (95.4%) - Near-perfect recall
Single-hop is the largest category (841 questions) and the most fundamental test: can you retrieve a specific fact from a specific session?
ByteRover achieves 95.4%, ahead of Hindsight (86.2%), Zep (74.1%), and Mem0 (67.1%). This reflects the quality of curation - when facts are extracted and organized cleanly, simple recall becomes almost trivial.
Multi-hop (85.1%) - The biggest leap over competitors
Multi-hop questions require connecting information scattered across multiple sessions - "Did Alice and Bob ever discuss the same restaurant?" demands retrieving from two or more separate sessions and synthesizing the answer.
This is where most systems fall apart. Mem0 scores 51.2%. Memobase drops to 46.9%. Even Hindsight, with its 4-way parallel retrieval, only reaches 70.8%.
ByteRover scores 85.1% - a +14.3 point advantage over Hindsight. The Context Tree's hierarchical structure (domain → topic → subtopic) allows the retrieval engine to traverse related sessions efficiently, rather than relying on flat similarity search.
Open Domain (77.2%) - Strong, with room to grow
Open domain questions test inference and commonsense reasoning - "Based on their conversations, what kind of person is Alice?" These require the system to go beyond explicit facts and draw conclusions.
ByteRover scores 89%, on par with Memobase (77.2%), better than Mem0 (72.9%), and Zep (67.7%). Hindsight leads this category at 95.1% - the one area where they outperform ByteRover. This likely reflects Hindsight's dedicated opinion network and behavioral reasoning layer (CARA), which is specifically designed for subjective inference.
This is an area we're actively investigating for future improvements.
Perhaps the most telling result isn't any single category - it's the gap between Run 1 and Run 2.
With Gemini 3 Flash across the board, ByteRover scores 90.9% - already outperforming Hindsight's best (89.6%). Upgrading to Gemini 3 Pro for justification pushes it to 92.2%.
Both experiments use the same Context Tree structure. The same retrieval pipeline. The same evaluation rules. The only variable is the model - and the lightweight model already matches the top of the leaderboard.
This means the architecture and engine are playing critical roles. A stronger model amplifies the results, but it isn't the source of the advantage. ByteRover's Context Tree is.
7. What's Next
LoCoMo is where the industry started. It's not where we're stopping.
LongMemEval - The harder test
Our next post will cover ByteRover 2.0's results on LongMemEval, a benchmark published at ICLR 2025 that pushes memory systems much further than LoCoMo:
500 questions across 6 memory ability categories, including knowledge updates, temporal reasoning, and multi-session synthesis.
A needle-in-haystack challenge, in the S variant, each question has just 1–3 relevant sessions buried among 45+ distractors.
Up to 1.5M tokens of conversation per question in the M variant,far beyond what any context window can handle.
Where LoCoMo tests whether your system can remember a 10-conversation corpus, LongMemEval tests whether it can find a needle in a field of haystacks. Stay tuned.
Try ByteRover now
ByteRover 2.0 is available now. If you're building AI agents, assistants, or any application that needs structured memories, try ByteRover CLI 2.0 now.
👉 Install ByteRover CLI:
curl -fsSL https://www.byterover.dev/install.sh | sh
Reproduce our results
Our benchmark suite is open source. You can run the same experiments we did - same dataset, same prompts, same evaluation pipeline.
We believe the best way to build trust in benchmark results is to let anyone reproduce them.
1. TL;DR
ByteRover 2.0 achieves 92.2% overall accuracy on the LoCoMo benchmark - matching or beating every major AI memory system.
94.4% on Temporal reasoning - best in class, ahead of Hindsight (83.8%) and Memobase (85.1%).
95.4% on Single-hop recall - surpassing every competitor.
85.1% on Multi-hop - outperforming Hindsight (70.8%) by 14.3 points.
77.2% on Open Domain - equivalent to Memobase (77.2%) and ahead of Mem0 (72.9%).
Built on a new Context Tree architecture and Retrieval System that retrieves smarter, not harder.
Still got 90.9% overall with Gemini-3-flash (whole benchmark process) - proving the architecture carries the weight, not the model.
2. The Problem
Your AI Forgets Everything
Think about the people you trust most - your doctor, your financial advisor, a close colleague. What makes them effective isn't just their expertise. It's that they remember. They remember what you told them last month, what worked before, what didn't, and what matters to you.
Now think about your AI assistant. Every new conversation starts from scratch. The preferences you shared last week? Gone. The complex decision you worked through over multiple sessions? Forgotten. You're stuck in a Groundhog Day loop - repeating yourself, re-explaining context, re-establishing trust.
This isn't a minor UX annoyance - it's a fundamental limitation. Without long-term memory, AI can't truly personalize, can't learn from past interactions, and can't handle tasks that unfold over days, weeks, or months. Customer support agents ask the same diagnostic questions on every call. Coding assistants forget the architecture decisions you made yesterday. Health assistants lose track of your symptoms over time.
The industry is racing to fix this
By 2025, every major AI platform - OpenAI, Anthropic, Google, Microsoft - has shipped some form of memory. But as even Mem0's own research acknowledges, extending context windows "merely delay rather than solve the fundamental limitation" - users jump between topics, burying critical information among irrelevant content.
This gap has spawned a wave of specialized memory systems, each taking a fundamentally different architectural approach:
Mem0 extracts salient memories from conversation pairs and applies discrete operations (add, update, delete) to maintain a memory store - with an enhanced graph variant that captures entity relationships.
Zep builds temporal knowledge graphs from conversations, encoding entities, relationships, and timestamps for time-aware retrieval.
Hindsight organizes memory into four logical networks (world facts, experiences, opinions, summaries) and implements a retain-recall-reflect pipeline with 4-way parallel retrieval.
Each claims to be the best. But claims are easy. The real question is: when you put them all through the same test, who actually remembers?
That's exactly what we did. We ran ByteRover 2.0 through the LoCoMo benchmark - the industry's most widely used test for long-term conversational memory - using our toughest competitor's own evaluation rules.
The results surprised even us.
3. What is LoCoMo?
LoCoMo dataset
Before we show you the numbers, let's talk about the test.
LoCoMo (Long-term Conversation Memory) is a benchmark created by researchers at UNC Chapel Hill, USC, and Snap Research, published at ACL 2024 - one of the top venues in natural language processing. It has since become the most widely adopted benchmark for evaluating AI memory systems, used by Mem0, Zep, Hindsight, Memobase, and others to validate their claims.
The setup
Imagine two people who've been chatting for months - about their jobs, relationships, hobbies, health, travel plans. These conversations span up to 35 sessions, averaging 600 turns and ~16,000 tokens per dialogue. Topics shift naturally. Details pile up. Some things change over time.
Now, quiz the AI on what was said.
LoCoMo does exactly this: 10 long-form conversations, 272 sessions, and 1,982 questions — each designed to test a different kind of memory.
The five question types
Category | What it tests | Example |
|---|---|---|
Single-hop (841 questions) | Simple factual recall from one session | "What is Alice's new job title?" |
Multi-hop (282 questions) | Connecting information across multiple sessions | "Did Alice and Bob ever discuss the same restaurant?" |
Temporal (321 questions) | Understanding time — what happened before, after, or when | "What did Alice say about her job before she got promoted?" |
Open Domain (92 questions) | Inference and commonsense reasoning beyond explicit text | "Based on their conversations, what kind of person is Alice?" |
Adversarial (446 questions) | Trick questions — the correct answer is often "this was never discussed" | "What did Alice say about her trip to Mars?" |
Why it matters
When the LoCoMo authors tested leading LLMs directly on a 4K context window, GPT-4, GPT-3.5, Llama-2, Mistral, even the best (GPT-4) scored just 32.1 F1, while humans scored 87.9 F1. That's a 56-point gap. Even GPT-3.5 with 16K context only reached 37.8 F1. LLMs alone, regardless of context length, can't do this. You need a memory system.
A note on methodology
Most memory builders on the market - Hindsight, Mem0, Zep, Memobase - report results on 4 categories, excluding adversarial. The primary metric is LLM-as-Judge accuracy: an LLM evaluates whether the system's answer is semantically correct given the ground truth. This has become the standard evaluation method across the field.
4. Experiment Setup
How We Evaluated ByteRover 2.0
Benchmarks are only meaningful when the rules are clear. Here's exactly how we ran ours.
Evaluation methodology
We adopted Hindsight's evaluation prompt - both for the LLM judge and the answer justifier. Hindsight currently holds the strongest independently-verified results on LoCoMo, so using their exact methodology ensures a direct, apples-to-apples comparison. No custom prompts, no scoring advantages.
Configuration
Component | Detail |
|---|---|
Evaluation prompt | Hindsight's LLM-as-Judge & Justifier prompt |
Curate/Query model | Gemini 3 Flash |
Justifier model | Gemini 3 Flash/Pro |
Judge model | Gemini 3-Flash |
Query format | Question only — no conversation ID or session hint |
Corpus | 272 sessions across 10 conversations |
Total queries | 1,982 |
The three-stage pipeline
Curate - Gemini 3 Flash processes each conversation session and organizes it into ByteRover's Context Tree
Retrieve - For each question, ByteRover retrieves relevant context with Gemini 3 Flash
Justify - Gemini 3 Flash/Pro synthesizes an answer using Hindsight's justifier prompt
Judge - Gemini 3 Flash evaluates whether the answer is correct against the ground truth, using Hindsight's judge prompt
What makes this a hard test
Two design choices make our evaluation deliberately harder than most:
1. No conversation hints: Many benchmarks pass the conversation ID alongside the question - essentially telling the system where to look. We don't. ByteRover receives only the raw question and must retrieve the relevant context from all 272 sessions on its own. This tests true retrieval quality, not pattern matching.
2. Independent judge: In Run 2 we use a separate, lighter model (Gemini 3 Flash) as the judge - distinct from justification model. This prevents the system from grading its own homework.
5. Results - The Comparison Table
Results
We ran two experiments, one with a lightweight model across the board, and one with a stronger curation and justification model. Both used Hindsight's exact evaluation prompt.
Experiment Configurations
Run 1 | Run 2 (Best) | |
|---|---|---|
Curate model | Gemini 3 Flash | Gemini 3 Flash |
Justifier model | Gemini 3 Flash | Gemini 3 Pro |
Judge model | Gemini 3 Flash | Gemini 3 Flash |
Overall accuracy | 90.9% | 92.2% |
Overall Leaderboard
System | Single-Hop | Multi-Hop | Open Domain | Temporal | Overall |
|---|---|---|---|---|---|
ByteRover 2.0 (Run 2 - best) | 95.4% | 85.1% | 77.2.1% | 94.4% | 92.2% |
ByteRover 2.0 (Run 1) | 93.9% | 82.6% | 77.2.0% | 94.4% | 90.9% |
Hindsight (Gemini-3) | 86.2% | 70.8% | 95.1% | 83.8% | 89.6% |
Memobase v0.0.37 | 70.9% | 46.9% | 77.2% | 85.1% | 75.8% |
Zep | 74.1% | 66.0% | 67.7% | 79.8% | 75.1% |
Mem0-Graph | 65.7% | 47.2% | 75.7% | 58.1% | 68.4% |
Mem0 | 67.1% | 51.2% | 72.9% | 55.5% | 66.9% |
OpenAI Memory | 63.8% | 42.9% | 62.3% | 21.7% | 52.9% |
Overall excludes adversarial category, consistent with how all competitors report. Competitor scores sourced from Hindsight benchmarks and Memobase evaluation.
What the two experiments tell us
Even with the lightweight Gemini 3 Flash across all stages, ByteRover 2.0 scores 90.9% - already matching Hindsight's best result (89.6%). Upgrading to Gemini 3 Pro for justification pushes the score to 92.2%, a +2.6% leap over the previous best.
This confirms that ByteRover's Context Tree architecture & Retrieval system are the primary driver - not the model. A stronger model amplifies the results, but even a budget model matches the top of the leaderboard.
The gap at a glance (Run 2 - best)
vs. Competitor | ByteRover Advantage |
|---|---|
vs. Hindsight (next best verified) | +2.6% overall |
vs. Memobase | +16.4% overall |
vs. Zep | +17.1% overall |
vs. Mem0 | +25.3% overall |
vs. OpenAI Memory | +39.3% overall |
6. Analysis
What the Numbers Tell Us
The leaderboard tells you who won. This section explains why.
Temporal reasoning (94.4%) - Best in class by a wide margin
Temporal questions are among the hardest in LoCoMo. They require understanding when things happened, in what order, and how facts changed over time "What did Alice say about her job before she got promoted?" or "How long after moving to New York did Bob start his new role?"
Most memory systems struggle here because they store facts without preserving chronological structure. Mem0 scores 55.5%. Zep, despite building temporal knowledge graphs specifically for this, reaches 79.8%. Hindsight gets to 83.8%.
ByteRover hits 94.4%. The Context Tree naturally preserves session order and timestamps during curation, so temporal relationships are baked into the structure - not reconstructed at query time.
Single-hop (95.4%) - Near-perfect recall
Single-hop is the largest category (841 questions) and the most fundamental test: can you retrieve a specific fact from a specific session?
ByteRover achieves 95.4%, ahead of Hindsight (86.2%), Zep (74.1%), and Mem0 (67.1%). This reflects the quality of curation - when facts are extracted and organized cleanly, simple recall becomes almost trivial.
Multi-hop (85.1%) - The biggest leap over competitors
Multi-hop questions require connecting information scattered across multiple sessions - "Did Alice and Bob ever discuss the same restaurant?" demands retrieving from two or more separate sessions and synthesizing the answer.
This is where most systems fall apart. Mem0 scores 51.2%. Memobase drops to 46.9%. Even Hindsight, with its 4-way parallel retrieval, only reaches 70.8%.
ByteRover scores 85.1% - a +14.3 point advantage over Hindsight. The Context Tree's hierarchical structure (domain → topic → subtopic) allows the retrieval engine to traverse related sessions efficiently, rather than relying on flat similarity search.
Open Domain (77.2%) - Strong, with room to grow
Open domain questions test inference and commonsense reasoning - "Based on their conversations, what kind of person is Alice?" These require the system to go beyond explicit facts and draw conclusions.
ByteRover scores 89%, on par with Memobase (77.2%), better than Mem0 (72.9%), and Zep (67.7%). Hindsight leads this category at 95.1% - the one area where they outperform ByteRover. This likely reflects Hindsight's dedicated opinion network and behavioral reasoning layer (CARA), which is specifically designed for subjective inference.
This is an area we're actively investigating for future improvements.
Perhaps the most telling result isn't any single category - it's the gap between Run 1 and Run 2.
With Gemini 3 Flash across the board, ByteRover scores 90.9% - already outperforming Hindsight's best (89.6%). Upgrading to Gemini 3 Pro for justification pushes it to 92.2%.
Both experiments use the same Context Tree structure. The same retrieval pipeline. The same evaluation rules. The only variable is the model - and the lightweight model already matches the top of the leaderboard.
This means the architecture and engine are playing critical roles. A stronger model amplifies the results, but it isn't the source of the advantage. ByteRover's Context Tree is.
7. What's Next
LoCoMo is where the industry started. It's not where we're stopping.
LongMemEval - The harder test
Our next post will cover ByteRover 2.0's results on LongMemEval, a benchmark published at ICLR 2025 that pushes memory systems much further than LoCoMo:
500 questions across 6 memory ability categories, including knowledge updates, temporal reasoning, and multi-session synthesis.
A needle-in-haystack challenge, in the S variant, each question has just 1–3 relevant sessions buried among 45+ distractors.
Up to 1.5M tokens of conversation per question in the M variant,far beyond what any context window can handle.
Where LoCoMo tests whether your system can remember a 10-conversation corpus, LongMemEval tests whether it can find a needle in a field of haystacks. Stay tuned.
Try ByteRover now
ByteRover 2.0 is available now. If you're building AI agents, assistants, or any application that needs structured memories, try ByteRover CLI 2.0 now.
👉 Install ByteRover CLI:
curl -fsSL https://www.byterover.dev/install.sh | sh
Reproduce our results
Our benchmark suite is open source. You can run the same experiments we did - same dataset, same prompts, same evaluation pipeline.
We believe the best way to build trust in benchmark results is to let anyone reproduce them.
1. TL;DR
ByteRover 2.0 achieves 92.2% overall accuracy on the LoCoMo benchmark - matching or beating every major AI memory system.
94.4% on Temporal reasoning - best in class, ahead of Hindsight (83.8%) and Memobase (85.1%).
95.4% on Single-hop recall - surpassing every competitor.
85.1% on Multi-hop - outperforming Hindsight (70.8%) by 14.3 points.
77.2% on Open Domain - equivalent to Memobase (77.2%) and ahead of Mem0 (72.9%).
Built on a new Context Tree architecture and Retrieval System that retrieves smarter, not harder.
Still got 90.9% overall with Gemini-3-flash (whole benchmark process) - proving the architecture carries the weight, not the model.
2. The Problem
Your AI Forgets Everything
Think about the people you trust most - your doctor, your financial advisor, a close colleague. What makes them effective isn't just their expertise. It's that they remember. They remember what you told them last month, what worked before, what didn't, and what matters to you.
Now think about your AI assistant. Every new conversation starts from scratch. The preferences you shared last week? Gone. The complex decision you worked through over multiple sessions? Forgotten. You're stuck in a Groundhog Day loop - repeating yourself, re-explaining context, re-establishing trust.
This isn't a minor UX annoyance - it's a fundamental limitation. Without long-term memory, AI can't truly personalize, can't learn from past interactions, and can't handle tasks that unfold over days, weeks, or months. Customer support agents ask the same diagnostic questions on every call. Coding assistants forget the architecture decisions you made yesterday. Health assistants lose track of your symptoms over time.
The industry is racing to fix this
By 2025, every major AI platform - OpenAI, Anthropic, Google, Microsoft - has shipped some form of memory. But as even Mem0's own research acknowledges, extending context windows "merely delay rather than solve the fundamental limitation" - users jump between topics, burying critical information among irrelevant content.
This gap has spawned a wave of specialized memory systems, each taking a fundamentally different architectural approach:
Mem0 extracts salient memories from conversation pairs and applies discrete operations (add, update, delete) to maintain a memory store - with an enhanced graph variant that captures entity relationships.
Zep builds temporal knowledge graphs from conversations, encoding entities, relationships, and timestamps for time-aware retrieval.
Hindsight organizes memory into four logical networks (world facts, experiences, opinions, summaries) and implements a retain-recall-reflect pipeline with 4-way parallel retrieval.
Each claims to be the best. But claims are easy. The real question is: when you put them all through the same test, who actually remembers?
That's exactly what we did. We ran ByteRover 2.0 through the LoCoMo benchmark - the industry's most widely used test for long-term conversational memory - using our toughest competitor's own evaluation rules.
The results surprised even us.
3. What is LoCoMo?
LoCoMo dataset
Before we show you the numbers, let's talk about the test.
LoCoMo (Long-term Conversation Memory) is a benchmark created by researchers at UNC Chapel Hill, USC, and Snap Research, published at ACL 2024 - one of the top venues in natural language processing. It has since become the most widely adopted benchmark for evaluating AI memory systems, used by Mem0, Zep, Hindsight, Memobase, and others to validate their claims.
The setup
Imagine two people who've been chatting for months - about their jobs, relationships, hobbies, health, travel plans. These conversations span up to 35 sessions, averaging 600 turns and ~16,000 tokens per dialogue. Topics shift naturally. Details pile up. Some things change over time.
Now, quiz the AI on what was said.
LoCoMo does exactly this: 10 long-form conversations, 272 sessions, and 1,982 questions — each designed to test a different kind of memory.
The five question types
Category | What it tests | Example |
|---|---|---|
Single-hop (841 questions) | Simple factual recall from one session | "What is Alice's new job title?" |
Multi-hop (282 questions) | Connecting information across multiple sessions | "Did Alice and Bob ever discuss the same restaurant?" |
Temporal (321 questions) | Understanding time — what happened before, after, or when | "What did Alice say about her job before she got promoted?" |
Open Domain (92 questions) | Inference and commonsense reasoning beyond explicit text | "Based on their conversations, what kind of person is Alice?" |
Adversarial (446 questions) | Trick questions — the correct answer is often "this was never discussed" | "What did Alice say about her trip to Mars?" |
Why it matters
When the LoCoMo authors tested leading LLMs directly on a 4K context window, GPT-4, GPT-3.5, Llama-2, Mistral, even the best (GPT-4) scored just 32.1 F1, while humans scored 87.9 F1. That's a 56-point gap. Even GPT-3.5 with 16K context only reached 37.8 F1. LLMs alone, regardless of context length, can't do this. You need a memory system.
A note on methodology
Most memory builders on the market - Hindsight, Mem0, Zep, Memobase - report results on 4 categories, excluding adversarial. The primary metric is LLM-as-Judge accuracy: an LLM evaluates whether the system's answer is semantically correct given the ground truth. This has become the standard evaluation method across the field.
4. Experiment Setup
How We Evaluated ByteRover 2.0
Benchmarks are only meaningful when the rules are clear. Here's exactly how we ran ours.
Evaluation methodology
We adopted Hindsight's evaluation prompt - both for the LLM judge and the answer justifier. Hindsight currently holds the strongest independently-verified results on LoCoMo, so using their exact methodology ensures a direct, apples-to-apples comparison. No custom prompts, no scoring advantages.
Configuration
Component | Detail |
|---|---|
Evaluation prompt | Hindsight's LLM-as-Judge & Justifier prompt |
Curate/Query model | Gemini 3 Flash |
Justifier model | Gemini 3 Flash/Pro |
Judge model | Gemini 3-Flash |
Query format | Question only — no conversation ID or session hint |
Corpus | 272 sessions across 10 conversations |
Total queries | 1,982 |
The three-stage pipeline
Curate - Gemini 3 Flash processes each conversation session and organizes it into ByteRover's Context Tree
Retrieve - For each question, ByteRover retrieves relevant context with Gemini 3 Flash
Justify - Gemini 3 Flash/Pro synthesizes an answer using Hindsight's justifier prompt
Judge - Gemini 3 Flash evaluates whether the answer is correct against the ground truth, using Hindsight's judge prompt
What makes this a hard test
Two design choices make our evaluation deliberately harder than most:
1. No conversation hints: Many benchmarks pass the conversation ID alongside the question - essentially telling the system where to look. We don't. ByteRover receives only the raw question and must retrieve the relevant context from all 272 sessions on its own. This tests true retrieval quality, not pattern matching.
2. Independent judge: In Run 2 we use a separate, lighter model (Gemini 3 Flash) as the judge - distinct from justification model. This prevents the system from grading its own homework.
5. Results - The Comparison Table
Results
We ran two experiments, one with a lightweight model across the board, and one with a stronger curation and justification model. Both used Hindsight's exact evaluation prompt.
Experiment Configurations
Run 1 | Run 2 (Best) | |
|---|---|---|
Curate model | Gemini 3 Flash | Gemini 3 Flash |
Justifier model | Gemini 3 Flash | Gemini 3 Pro |
Judge model | Gemini 3 Flash | Gemini 3 Flash |
Overall accuracy | 90.9% | 92.2% |
Overall Leaderboard
System | Single-Hop | Multi-Hop | Open Domain | Temporal | Overall |
|---|---|---|---|---|---|
ByteRover 2.0 (Run 2 - best) | 95.4% | 85.1% | 77.2.1% | 94.4% | 92.2% |
ByteRover 2.0 (Run 1) | 93.9% | 82.6% | 77.2.0% | 94.4% | 90.9% |
Hindsight (Gemini-3) | 86.2% | 70.8% | 95.1% | 83.8% | 89.6% |
Memobase v0.0.37 | 70.9% | 46.9% | 77.2% | 85.1% | 75.8% |
Zep | 74.1% | 66.0% | 67.7% | 79.8% | 75.1% |
Mem0-Graph | 65.7% | 47.2% | 75.7% | 58.1% | 68.4% |
Mem0 | 67.1% | 51.2% | 72.9% | 55.5% | 66.9% |
OpenAI Memory | 63.8% | 42.9% | 62.3% | 21.7% | 52.9% |
Overall excludes adversarial category, consistent with how all competitors report. Competitor scores sourced from Hindsight benchmarks and Memobase evaluation.
What the two experiments tell us
Even with the lightweight Gemini 3 Flash across all stages, ByteRover 2.0 scores 90.9% - already matching Hindsight's best result (89.6%). Upgrading to Gemini 3 Pro for justification pushes the score to 92.2%, a +2.6% leap over the previous best.
This confirms that ByteRover's Context Tree architecture & Retrieval system are the primary driver - not the model. A stronger model amplifies the results, but even a budget model matches the top of the leaderboard.
The gap at a glance (Run 2 - best)
vs. Competitor | ByteRover Advantage |
|---|---|
vs. Hindsight (next best verified) | +2.6% overall |
vs. Memobase | +16.4% overall |
vs. Zep | +17.1% overall |
vs. Mem0 | +25.3% overall |
vs. OpenAI Memory | +39.3% overall |
6. Analysis
What the Numbers Tell Us
The leaderboard tells you who won. This section explains why.
Temporal reasoning (94.4%) - Best in class by a wide margin
Temporal questions are among the hardest in LoCoMo. They require understanding when things happened, in what order, and how facts changed over time "What did Alice say about her job before she got promoted?" or "How long after moving to New York did Bob start his new role?"
Most memory systems struggle here because they store facts without preserving chronological structure. Mem0 scores 55.5%. Zep, despite building temporal knowledge graphs specifically for this, reaches 79.8%. Hindsight gets to 83.8%.
ByteRover hits 94.4%. The Context Tree naturally preserves session order and timestamps during curation, so temporal relationships are baked into the structure - not reconstructed at query time.
Single-hop (95.4%) - Near-perfect recall
Single-hop is the largest category (841 questions) and the most fundamental test: can you retrieve a specific fact from a specific session?
ByteRover achieves 95.4%, ahead of Hindsight (86.2%), Zep (74.1%), and Mem0 (67.1%). This reflects the quality of curation - when facts are extracted and organized cleanly, simple recall becomes almost trivial.
Multi-hop (85.1%) - The biggest leap over competitors
Multi-hop questions require connecting information scattered across multiple sessions - "Did Alice and Bob ever discuss the same restaurant?" demands retrieving from two or more separate sessions and synthesizing the answer.
This is where most systems fall apart. Mem0 scores 51.2%. Memobase drops to 46.9%. Even Hindsight, with its 4-way parallel retrieval, only reaches 70.8%.
ByteRover scores 85.1% - a +14.3 point advantage over Hindsight. The Context Tree's hierarchical structure (domain → topic → subtopic) allows the retrieval engine to traverse related sessions efficiently, rather than relying on flat similarity search.
Open Domain (77.2%) - Strong, with room to grow
Open domain questions test inference and commonsense reasoning - "Based on their conversations, what kind of person is Alice?" These require the system to go beyond explicit facts and draw conclusions.
ByteRover scores 89%, on par with Memobase (77.2%), better than Mem0 (72.9%), and Zep (67.7%). Hindsight leads this category at 95.1% - the one area where they outperform ByteRover. This likely reflects Hindsight's dedicated opinion network and behavioral reasoning layer (CARA), which is specifically designed for subjective inference.
This is an area we're actively investigating for future improvements.
Perhaps the most telling result isn't any single category - it's the gap between Run 1 and Run 2.
With Gemini 3 Flash across the board, ByteRover scores 90.9% - already outperforming Hindsight's best (89.6%). Upgrading to Gemini 3 Pro for justification pushes it to 92.2%.
Both experiments use the same Context Tree structure. The same retrieval pipeline. The same evaluation rules. The only variable is the model - and the lightweight model already matches the top of the leaderboard.
This means the architecture and engine are playing critical roles. A stronger model amplifies the results, but it isn't the source of the advantage. ByteRover's Context Tree is.
7. What's Next
LoCoMo is where the industry started. It's not where we're stopping.
LongMemEval - The harder test
Our next post will cover ByteRover 2.0's results on LongMemEval, a benchmark published at ICLR 2025 that pushes memory systems much further than LoCoMo:
500 questions across 6 memory ability categories, including knowledge updates, temporal reasoning, and multi-session synthesis.
A needle-in-haystack challenge, in the S variant, each question has just 1–3 relevant sessions buried among 45+ distractors.
Up to 1.5M tokens of conversation per question in the M variant,far beyond what any context window can handle.
Where LoCoMo tests whether your system can remember a 10-conversation corpus, LongMemEval tests whether it can find a needle in a field of haystacks. Stay tuned.
Try ByteRover now
ByteRover 2.0 is available now. If you're building AI agents, assistants, or any application that needs structured memories, try ByteRover CLI 2.0 now.
👉 Install ByteRover CLI:
curl -fsSL https://www.byterover.dev/install.sh | sh
Reproduce our results
Our benchmark suite is open source. You can run the same experiments we did - same dataset, same prompts, same evaluation pipeline.
We believe the best way to build trust in benchmark results is to let anyone reproduce them.