Article
TL;DR
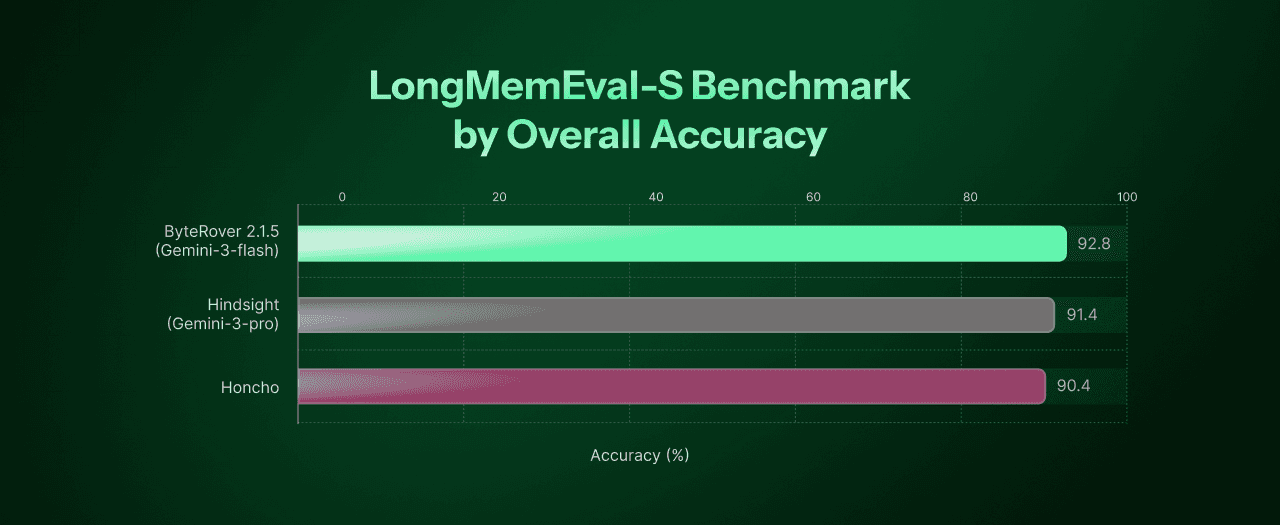
ByteRover 2.1.5 scores 92.8% on LongMemEval-S - the highest accuracy in the market (compared to other existing solutions). To prove that results are accurate in real production:
We benchmarked on the hardest long-term memory benchmark in the field (LongMemEval-S)
>92% Accuracy: ByteRover can find the right answers among 23,867 documents with just 1-3 relevant sessions per question.
Massive token saving with Flash Model: You achieve state-of-the-art memory retrieval without paying frontier-model API prices at scale. Options to connect with external LLM providers.
1.6s p50 latency: Memory retrieval happens almost instantly, keeping the user experience flowing without long pauses.
How these numbers are translated into actual agent behavior:
99% on Knowledge Update - Agents adapt to changing requirements instead of clinging to outdated context.
97-99% on Single-Session recall - Users never have to repeat their constraints, details, or preferences.
92% on Temporal Reasoning - Agents understand the exact timeline and order of operations, crucial for executing multi-step workflows.
84% on Multi-Session - Agents successfully synthesize complex, long-running projects by connecting scattered facts across different days.

Recap - Where We Left Off
In our previous post, we introduced ByteRover 2.0 and its results on the LoCoMo benchmark - the most widely adopted test for long-term conversational AI memory.
The headline: 92.2% overall accuracy, ahead of every established memory system we tested against - Hindsight (89.6%), Memobase (75.8%), Zep (75.1%), Mem0 (66.9%), and OpenAI Memory (52.9%).
We also introduced the Context Tree - ByteRover's hierarchical approach to organizing conversational knowledge - and showed that even a lightweight Flash model could match the top of the leaderboard, proving the architecture carries the weight.
We teased a harder test. This is that post.
What's new in v2.1.5:
Since our LoCoMo evaluation on v2.0, we've shipped improvements to ByteRover's retrieval engine and curation pipeline. This post covers:
LongMemEval-S - a harder, more recent benchmark (ICLR 2025) that tests whether ByteRover can find needles in a field of haystacks
Updated LoCoMo results - re-evaluated on v2.1.5 to track our progress
Latency - because accuracy without speed is a research demo, not a product
Why We Chose LongMemEval
LongMemEval was published at ICLR 2025 - one of the top machine learning venues - by researchers at UNC Chapel Hill and Microsoft Research. It was designed to address a question that LoCoMo can only partially answer: what happens when the conversation history gets really, really long?
LoCoMo tests memory across 10 conversations with 272 sessions. That's meaningful - but manageable. LongMemEval pushes further:
500 questions across 6 memory ability categories
The S variant buries 1-3 relevant sessions among 45+ distractor sessions per question - a true needle-in-haystack challenge
The M variant scales to ~1.5M tokens of conversation per question - far beyond any context window
Where LoCoMo asks "can you remember a corpus?", LongMemEval asks "can you find what matters in a sea of noise?"
The six categories
Category | Queries | What it tests |
|---|---|---|
Single-Session User | 70 | Recall facts the user shared in a single session |
Single-Session Assistant | 56 | Recall facts the assistant provided in a single session |
Single-Session Preference | 30 | Remember user preferences expressed in a single session |
Knowledge Update | 78 | Track facts that changed over time — the latest answer isn't always the first one |
Temporal Reasoning | 133 | Understand when things happened and in what order |
Multi-Session | 133 | Connect information scattered across multiple sessions |
Why it's harder than LoCoMo
In LoCoMo, the full corpus is 272 sessions across 10 conversations. The system ingests everything and answers questions over the whole set.
In LongMemEval-S, each question comes with its own haystack - approximately 48 sessions per question, of which only 1-3 are relevant. ByteRover's context tree for this benchmark contains 23,867 documents. The retrieval engine has to find the right needle every time.
When the LongMemEval authors gave GPT-4o the full ~115k-token conversation history, it scored just 60.6% - down from 87.0% when given only the relevant sessions. Even frontier LLMs with long context windows can't brute-force their way through this. You need a memory system that retrieves precisely.
Experiment Setup
How we evaluated
We ran two experiments on LongMemEval-S, varying the model configuration to test how much the model matters versus the architecture.
Run 1 (Best) | Run 2 | |
|---|---|---|
ByteRover version | 2.1.5 | 2.1.5 |
Curation model | Gemini 3 Flash | Gemini 3.1 Pro |
Justifier model | Gemini 3.1 Pro | Gemini 3.1 Pro |
Judge model | Gemini 3 Flash | Gemini 3.1 Pro |
Context tree | 23,867 documents | 23,867 documents |
Queries | 500 | 500 |
Eval duration covers retrieval, justification, and judging only. Curation (building the Context Tree) is a one-time step performed before evaluation.
The Benchmark pipeline
The pipeline follows the same structure as our LoCoMo evaluation:
Curate - ByteRover ingests all sessions and builds a Context Tree, extracting structured key facts with metadata per session
Retrieve - For each question, the retrieval engine searches the Context Tree for relevant facts across 23,867 documents
Justify - A justifier model synthesizes an answer from the retrieved context
Judge - A separate model evaluates whether the answer is semantically correct given the ground truth
What stayed the same
Same ByteRover retrieval engine and pipeline across both runs
No question hints - ByteRover receives only the raw question, no session IDs or metadata
Judge is always a separate model from the curation pipeline - the system doesn't grade its own work
Why two runs?
The same question we asked in our LoCoMo post: does a more expensive model produce better results?
Spoiler: it doesn't. Run 1 (Flash) scores 92.8%. Run 2 (Pro) scores 92.2%. We'll unpack this in the analysis.
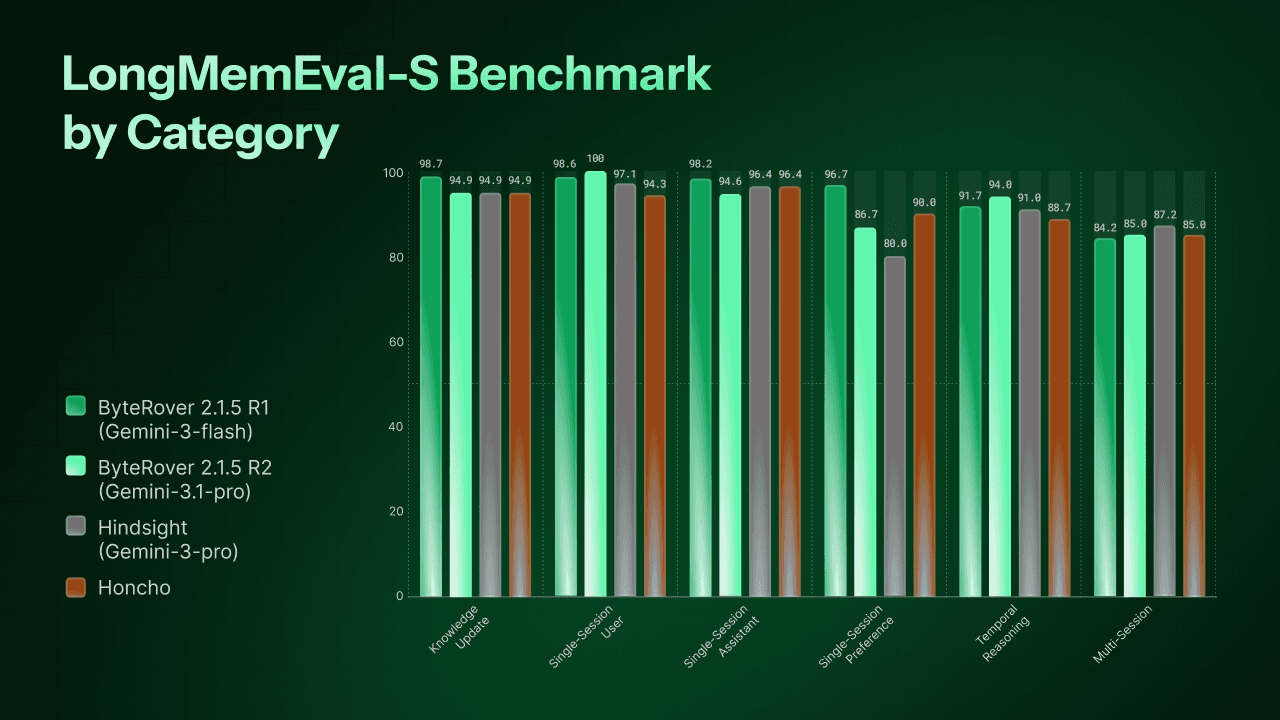
LongMemEval-S Results
The results
Category | Queries | ByteRover 2.1.5 Run 1 - Gemini-3-flash | ByteRover | Hindsight | HonCho |
|---|---|---|---|---|---|
Knowledge Update | 78 | 98.7% (77/78) | 94.9% (74/78) | 94.9% | 94.9% |
Single-Session User | 70 | 98.6% (69/70) | 100% (70/70) | 97.1% | 94.3% |
Single-Session Assistant | 56 | 98.2% (55/56) | 94.6% (53/56) | 96.4% | 96.4% |
Single-Session Preference | 30 | 96.7% (29/30) | 86.7% (26/30) | 80.0% | 90.0% |
Temporal Reasoning | 133 | 91.7% (122/133) | 94.0% (125/133) | 91.0% | 88.7% |
Multi-Session | 133 | 84.2% (112/133) | 85.0% (113/133) | 87.2% | 85% |
Overall | 500 | 92.8% (464/500) | 92.2% (461/500) | 91.4% | 90.4% |
ByteRover Run 1 wins 5 out of 6 categories against Hindsight - using a Flash-tier curation and judge model.
A note on model configurations
Each system in this comparison uses a different model stack. Hindsight uses Gemini 3 Pro. Honcho uses a multi-model pipeline - Gemini 2.5 Flash Lite for derivation (deriver) and Claude Haiku 4.5 for retrieval and answer generation (dialectic), GPT-4o for Judging, dream and summary steps are disabled in their benchmark. ByteRover uses Gemini 3 Flash for curation and judging, with Gemini 3.1 Pro for justification.
This is the reality of benchmarking in 2026 - there is no single standard model configuration across the field. Every team optimizes for their own architecture.
What makes ByteRover's result notable is which models it uses. Gemini 3 Flash is the lightest model in this comparison - cheaper and faster than both Gemini 3 Pro and Claude Haiku 4.5. ByteRover achieves the highest overall score with the most cost-efficient configuration. The architecture does the heavy lifting, not the model budget.
Where ByteRover excels
Knowledge Update (98.7%) - These questions test whether the system can track facts that change over time. "Where does Alice work?" has a different answer in session 5 than in session 20. ByteRover misses just 1 out of 78 questions. The Context Tree's session-level structure naturally preserves the chronological order of facts, so the latest update doesn't overwrite the history - it layers on top.
Single-Session Recall (96.7-98.6%) - Three categories test whether the system can retrieve specific information from a single session: what the user said, what the assistant said, and what preferences the user expressed. ByteRover Run 1 scores 98.6%, 98.2%, and 96.7% respectively - missing just 4 questions out of 156 combined.
Single-Session Preference (+16.7 over Hindsight, +6.7 over Honcho) - The standout gap. Preferences are subtle - "I prefer window seats" or "I don't like spicy food" - and easy to lose in a long conversation. ByteRover captures 29 out of 30. Hindsight captures 24 out of 30. Honcho captures 27 out of 30. The Context Tree's curation step extracts these as first-class facts, not afterthoughts.
Temporal Reasoning - Both runs are strong: 91.7% (Run 1) and 94.0% (Run 2). Ahead of Honcho (88.7%) and Hindsight (91.0%). Understanding when things happened is a natural strength of the Context Tree's session-ordered structure.
Where there's room to grow
Multi-Session (84.2–85.0%) - This is the hardest category in both LoCoMo and LongMemEval. It requires connecting information scattered across multiple sessions - the same challenge as LoCoMo's multi-hop category, where ByteRover scored 85.1%.
Hindsight leads here at 87.2%, with Honcho at 85.0%. ByteRover is competitive but not yet ahead. Their architectures - Hindsight's 4-way parallel retrieval and Honcho's reasoning-based dialectic agent - are specifically designed for cross-session synthesis. This is an area we're actively working to improve.
23,867 documents. 500 questions. 464 correct.
To put the challenge in perspective: for each question, ByteRover's retrieval engine searches through a context tree built from approximately 48 sessions, of which only 1–3 contain the answer. It finds the right needle 92.8% of the time.
Updated LoCoMo Results - v2.1.5
The benchmark we keep running
In our first blog we committed to reproducibility. When we ship improvements, we re-run the benchmark. v2.1.5 brings significant changes to ByteRover's retrieval engine and curation pipeline - so we ran LoCoMo again, with the same model configuration as our previous best result.
The numbers moved.
Results
Category | ByteRover 2.1.5 | ByteRover 2.0 | Hindsight | HonCho | Memobase v0.0.37 | Zep | Mem0 | OpenAI Memory |
|---|---|---|---|---|---|---|---|---|
Single-Hop | 97.5%(820/841) | 95.4% | 86.2% | 93.2% | 70.9% | 74.1% | 67.1% | 63.8% |
Multi-Hop | 93.3% (263/282) | 85.1% | 70.8% | 84.0% | 46.9% | 66.0% | 51.2% | 42.9% |
Open Domain | 85.9% | 77.2% | 95.1% | 77.1% | 77.2% | 67.7% | 72.9% | 62.3% |
Temporal | 97.8% (314/321) | 94.4% | 83.8% | 88.2% | 85.1% | 79.8% | 55.5% | 21.7% |
Overall | 96.1% | 92.2% | 89.6% | 89.9% | 75.8% | 75.1% | 66.9% | 52.9% |
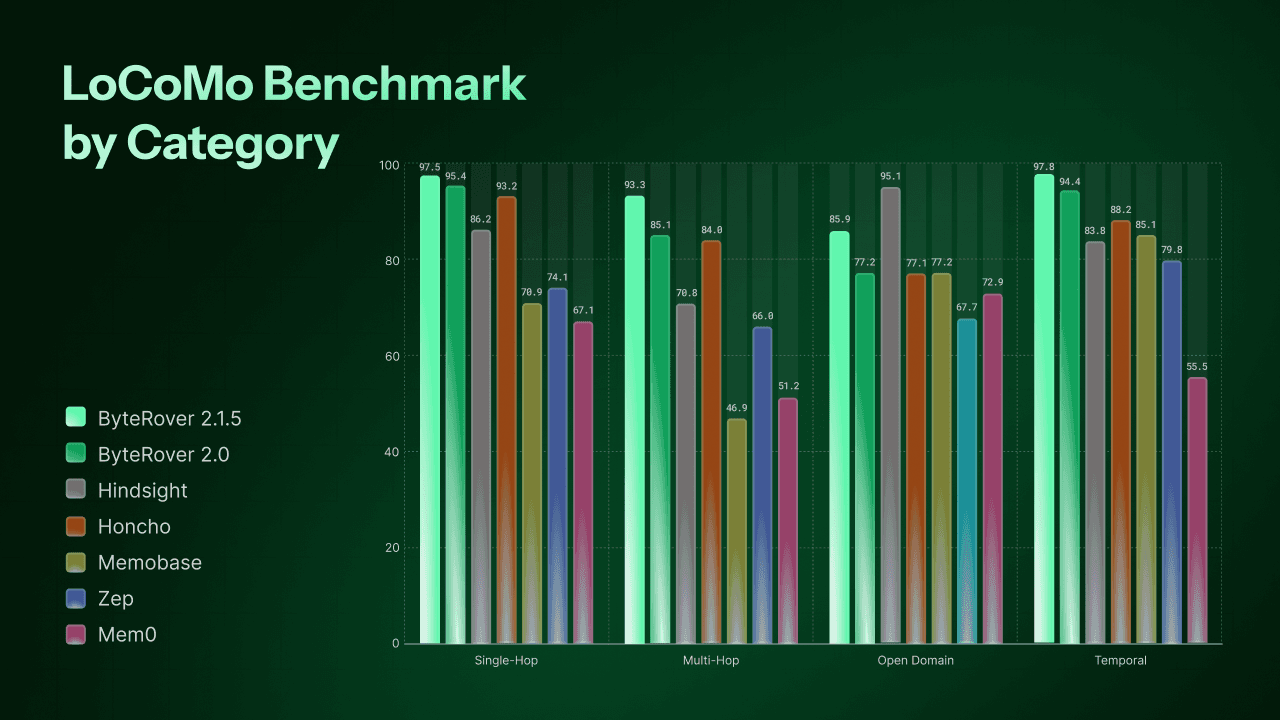
Overall excludes adversarial, consistent with how all competitors report. Competitor scores sourced from Hindsight benchmarks, Memobase evaluation, and Honcho benchmarks. ByteRover evaluated using Gemini 3 Flash (curate/query/judge) + Gemini 3.1 Pro (justifier).
What changed - and where it matters
The improvements in v2.1.5 are not evenly distributed. They land hardest in exactly the two categories where v2.0 had the most room to grow.
Multi-Hop: 85.1% → 93.3% (+8.2 points)
Multi-hop was our most challenging LoCoMo category - questions that require connecting facts scattered across multiple sessions. v2.1.5 closes this gap dramatically, now outperforming the last record (ByteRover 2.0-Run 2: 85.1%) by +8.2 points. The retrieval engine improvements in v2.1.5 are most visible here, where traversing related sessions efficiently makes the biggest difference.
Open Domain: 77.2% → 85.9% (+8.7 points)
Open domain questions require inference beyond explicit facts - "based on their conversations, what kind of person is Alice?" This was v2.0's weakest category. v2.1.5 gains 8.7 points. Hindsight (95.1%) still leads here - their dedicated opinion network and behavioral reasoning layer are specifically designed for subjective inference. This remains an area we're actively improving.
Single-Hop: 95.4% → 97.5% (+2.1 points)
Already strong, now near perfect. 820 out of 841 single-hop questions answered correctly.
Temporal: 94.4% → 97.8% (+3.4 points)
Consistently ByteRover's strongest dimension. The Context Tree's session-ordered structure makes temporal reasoning a natural strength - and v2.1.5 extends that lead further.
Adversarial: 97.3% (434/446)
We report this separately, consistent with our first blog. Adversarial questions test whether the system correctly handles false premises and questions about things that were never discussed. 97.3% means ByteRover almost never fabricates an answer to a trick question - a critical property for production deployments.
Same model. Better engine.
v2.1.5 uses the same model configuration as our previous best result (Gemini 3 Flash for curation and judging, Gemini 3.1 Pro for justification). The accuracy improvement from 92.2% to 96.1% comes entirely from engine and pipeline improvements - not from a more expensive model.
Latency - Production-Ready, Not Just Benchmark-Ready
The question nobody asks - but every user feels
When evaluating memory systems, the conversation always ends up in the same place: accuracy scores, benchmark rankings, architecture comparisons. Almost nobody asks: how fast is it?
Your users will.
A memory system that retrieves the right answer in 10 seconds is technically correct. But in a real conversation, a 10-second pause before a response isn't a feature - it's a broken experience. Accuracy without speed is a research demo. Accuracy with speed is a product.
These latency numbers are not only from a tuned benchmark environment. ByteRover's evaluation runs on the same engine configuration that ships to production - what you see here is what your users get.
ByteRover's cold latency on LongMemEval-S
Cold latency is the hardest test: no cache, no warm-up, no shortcuts. Every query is a fresh search through 23,867 documents.
Metric | Result |
|---|---|
Mean | 1.3s |
p50 | 1.6s |
p95 | 2.3s |
p99 | 2.5s |
p99 under 2.5 seconds. That means 99 out of every 100 queries - even cold, even searching through nearly 24,000 documents - resolve in under 2.5 seconds.
The median user waits 1.6 seconds. That's not a loading spinner - that's a response.
Why cold latency matters more than average
Averages hide the outliers your users actually complain about. p95 and p99 tell you what your worst-case experience looks like in production - the queries that arrive at peak load, on the longest conversations, with the most complex context trees.
ByteRover's p95-to-p99 spread is just 0.2 seconds (2.3s → 2.5s). The latency distribution is tight. There are no hidden spikes. What you see in benchmarks is what you get in production.
What this means for real deployments
AI assistants - users expect near-instant responses. Sub-2s retrieval keeps ByteRover invisible, the way infrastructure should be.
Autonomous agents - agents fire memory queries in loops. 1.3s mean latency compounds favorably over hundreds of calls per session.
Customer support - live conversations can't pause for 10 seconds while memory catches up. 1.6s p50 keeps the conversation flowing.
Speed is not a nice-to-have. For production memory layers, it is the difference between a system that ships and a system that doesn't.
The Model Is Interchangeable. The Architecture Isn't.
Run 1 uses Gemini 3 Flash for curation and judging, with Gemini 3.1 Pro for justification. Run 2 uses Pro across the board. Run 1 wins - 92.8% vs 92.2% on LongMemEval-S, at a third of the evaluation time.
This is the second time we've seen this pattern. In our LoCoMo v2.0 evaluation, Gemini 3 Flash already delivered top-tier results across the established competitor set. Now with v2.1.5, the same lightweight configuration scores 96.1% on LoCoMo and 92.8% on LongMemEval-S - across two independent benchmarks.
If the model were the primary driver of accuracy, Run 2 would win. It doesn't.
The reason is straightforward. The Context Tree organizes conversational knowledge before any query arrives - by domain, topic, and session. When a question comes in, the right facts are already structured and ready to surface. By the time the model is asked to generate an answer, the retrieval has done the hard work. The model's job is synthesis, not search.
A capable model on a weak retrieval system will hallucinate confidently. A lightweight model on a strong retrieval system will find the right answer - faster and cheaper.
ByteRover is the retrieval system. The model is interchangeable.
What's Next
Continuous benchmarking
A benchmark result is a snapshot. We believe the only way to build trust in a memory system is to keep measuring - every release, every improvement, every regression.
Starting with our next release, we're committing to running the full benchmark suite - both LoCoMo and LongMemEval-S - on every significant version of ByteRover. Results will be published openly so anyone can track our progress over time.
Multi-model evaluation
Our current results use the Gemini model family. Upcoming benchmarks will extend evaluation across multiple model providers - including GPT - to give a complete picture of how ByteRover performs regardless of the underlying model.
This matters because real deployments don't all use the same model. ByteRover's architecture is model-agnostic by design, and our benchmark results should reflect that.