February 27, 2026
Product Release
ByteRover - Curated, stateful memory for OpenClaw.
OpenClaw’s original vector-based and keyword-based memory system helped manage memory so the AI could recall past interactions and build on them over time. It stores context in markdown files and retrieves information using semantic vector search.
While this approach works for basic recall, the community has noticed its limitations in persisting and structuring long-term memory in a way that remains reliable over time.
To address this, the qmd memory plugin was recently introduced for OpenClaw. qmd acts as a semantic retrieval layer for background tasks. As a memory plugin, it provides OpenClaw with a more efficient way to store and search historical context compared to the default memory backend. The OpenClaw community has responded positively to this improvement.
However, we believe there are many more gaps to be addressed. In this blog, we will share about our views on what aspects current OpenClaw’s memory system could improve, and how we addressed them in our latest version of ByteRover CLI.

Limitation of retrieval-only memory layer (what is currently in OpenClaw, and its qmd memory plugin)
A retrieval-only memory layer limits how humans can shape, control, and evolve memory over time. It improves search performance, but it does not fundamentally change how knowledge is structured, curated, or governed.
At ByteRover, we have been building knowledge curation and retrieval systems specifically for coding agents. One thing we consistently observed is that users in our community always want to curate highly specialized knowledge for their agents. They want control over what becomes durable memory and how that memory is organized.
That’s why we brought this curation capability and portability to OpenClaw.
ByteRover brings stateful and curated memory for OpenClaw agents
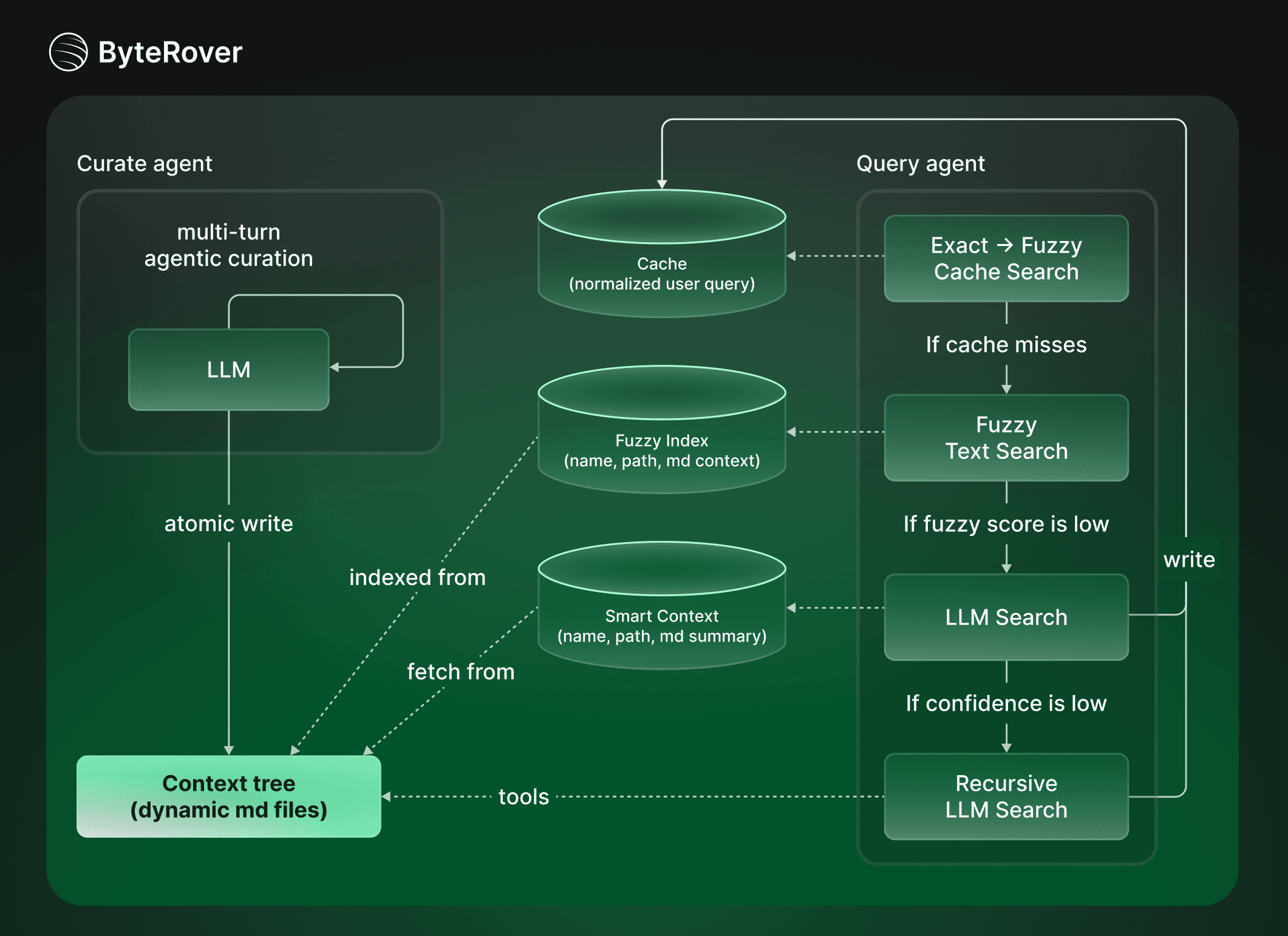
LLM-enabled curation capability & context tree structure that enables 92.19% retrieval accuracy - highest on the market.
Most memory retrieval systems on the market, including OpenClaw, and the QMD plugin, rely primarily on vector similarity search. Vector search works well for finding semantically similar text. But memory is more than similarity. Embeddings do not capture why a piece of knowledge matters, how it relates to other knowledge, or whether it is still valid.
ByteRover takes a different approach. Instead of treating memory as a passive store, we apply LLM-enabled curation upfront to actively structure and organize knowledge before storage. A ByteRover agent intelligently curates, synthesizes, and arranges information into a context tree organized as modular md files with a clear hierarchy (domain → topic → subtopic).
Retrieval is then performed by an agent that searches directly across these structured knowledge files, enabling richer context, better reasoning, and more reliable recall than similarity-based methods.
High-quality curation, structured organization of memory drives our retrieval benchmark results: overall 92.19%, which is highest on the market. Read more on our benchmark.
Memory that thinks and reasons
Every interaction with the Context Tree produces structured feedback describing what was added, updated, merged, skipped, or failed, and why. This creates three properties that retrieval-only memory cannot provide:
Auditability for humans
You can inspect exactly what an agent learned, when it learned it, and the reasoning behind each decision. Knowledge becomes traceable rather than opaque.
Failure awareness for agents
If memory curation fails due to missing data, unavailable sources, or conflicts, the agent is explicitly informed. The system surfaces gaps instead of silently ignoring them.
Continuity across sessions
Memory state lives in files, not in ephemeral context windows. When an agent resumes work after a restart, crash, or timeout, it can reconstruct exactly where it left off.
Memory portability on cloud with version control & management
Memory workspace on cloud with version control and team management capability have been the highlight of what we have been building for coding agents. With ByteRover, you can push OpenClaw memory to our cloud-based memory workspace so that it can be used by any autonomous AI agent that you, or your team, has. This means shared memory across different OpenClaw agents, or your existing autonomous agentic stack, or any new agentic stack coming up in the future.
Retrieval optimized for speed, precision, and token usage
The “retrieval task” for autonomous agent cannot just be one-shot operation (what is popular on the market) hoping to get “the best context” without any “intelligent reasoning”.
As ByteRover’s memory is structured with reasoning and file-based, retrieval does not rely solely on vector similarity.
Instead, ByteRover uses a tiered retrieval pipeline:
Cache lookup → full-text search → LLM-powered search
This approach has several advantages:
Faster retrieval for common queries
Lower token usage by avoiding unnecessary LLM calls
More task-relevant results grounded in structured knowledge rather than semantic similarity alone.
Mode of use: ByteRover & OpenClaw
A three-layer memory architecture for OpenClaw
Originally, OpenClaw provides two built-in memory layers that exist by default in every agent workspace: daily memory, workspace memory. ByteRover introduces a third memory layer, designed specifically to support structured knowledge for OpenClaw agents.
OpenClaw stores memory directly in the agent workspace as plain Markdown files:
MEMORY.md contains durable knowledge such as preferences, rules, and architectural decisions. It is loaded at the start of each private session and serves as the agent’s long-term notes.
Daily memory files (memory/YYYY-MM-DD.md) are append-only logs that capture short-term context, what happened recently and where work left off. At session start, OpenClaw automatically loads today’s and yesterday’s files.
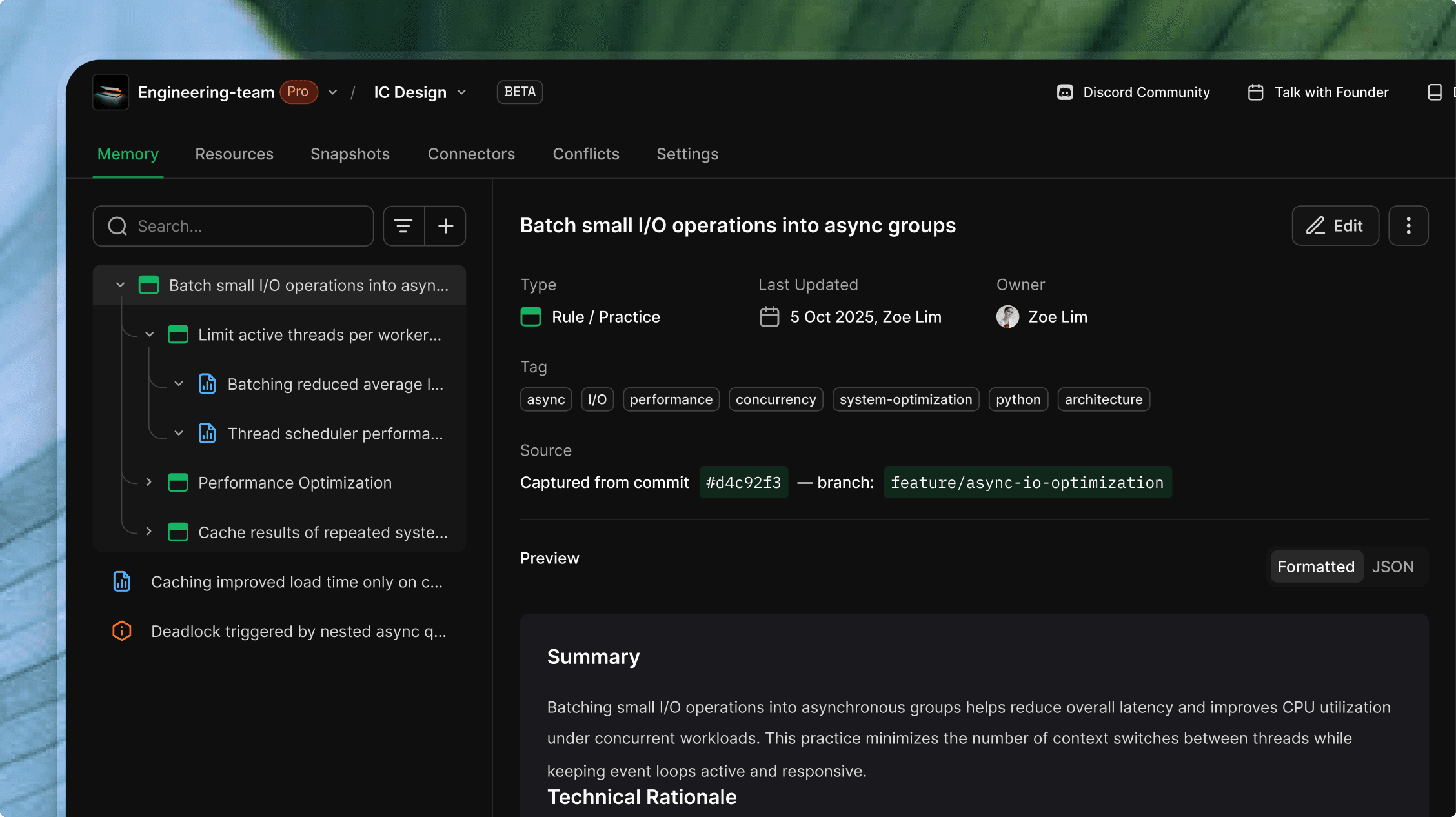
ByteRover adds a third memory layer: the Context Tree. Unlike OpenClaw’s flat text files, the Context Tree is a structured knowledge base curated by an agent using LLM reasoning, as discussed above.
Layer | Source | Lifetime | Written By | Example |
|---|---|---|---|---|
Context Tree | ByteRover ( | Persistent, LLM-curated | Agent via sandbox curation | “auth module has circular dependency on billing (severity: high, 12 import paths affected)” |
Workspace Memory | OpenClaw ( | Persistent, manually curated | Agent or human | “Always use dependency injection for service constructors. Never commit .env files.” |
Daily Memory | OpenClaw ( | Persistent, append-only | Agent during session | “2026-02-19: Scanned 180 of 200 files. Paused at src/billing/—retry tomorrow.” |
These layers complement one another. When an agent starts a new session, it loads MEMORY.md to understand durable preferences, reads memory/2026-02-18.md to regain recent context, and queries the Context Tree for structured domain knowledge.
Workspace Memory tells the agent how to behave
Daily Memory tells the agent where it left off
The Context Tree tells the agent what it knows
Together, these layers enable agents to maintain continuity, and structured knowledge as they become more autonomous.
Using ByteRover in combination with QMD
To help you visualize the difference in modes of use with OpenClaw, ByteRover, and qmd. Here are the quick comparison tables:
OpenClaw | OpenClaw + QMD | OpenClaw + ByteRover | OpenClaw + QMD + ByteRover | |
|---|---|---|---|---|
qmd’s vector-based retrieval | ❌ | ✅ | ✅ | |
byterover’s stateful curation | ❌ | ✅ | ✅ | |
byterover’s cache→full-text→agentic-search retrieval | ❌ | ✅ |
Below is a comparison table that show the difference OpenClaw + QMD versus ByteRover:
Dimension | OpenClaw + QMD | OpenClaw + ByteRover |
|---|---|---|
Core role | Static memory | Living, intelligently curated and recalled memory layer |
Mental model | “Fast recall from docs/notes” | “Shared understanding that grows over time” |
Memory structure and organization | Unstructured markdown chunks (just memory.md / | Structured knowledge (domains, topics, relations, rules) |
Persistence across sessions | ✅ Yes (indexed files) | ✅ Yes (files on disk) |
Who decides what is remembered | You (whatever you index) | LLM supports you as much as you want |
Memory storing style | Index + embed | ADD / UPDATE / MERGE / DELETE with LLM reasonings |
Memory transparency | Medium (files readable, index opaque) | Full (readable markdown, diffable) |
Auditability | Low | Very high (who/why/when per entry) |
Retrieval style in OpenClaw | BM25 + vector + rerank search | Fuzzy search + Agentic File Search |
“Understands why this matters?” | ❌ No | Yes (Narrative + rules + flow) |
Failure awareness (OOD / gaps) | ❌ No | Explicit OOD + feedback loop |
Local-first | Yes, fully local | Local, but with Cloud sync support |
Infra complexity | Low (binary + index) | Low (files + CLI) |
Best OpenClaw use case | Searching large local note/doc sets | Long-running agents, research, coding, trading, multi-agent systems |
What OpenClaw becomes | A better search-augmented agent | A stateful collaborator |
In summary, these are what ByteRover adds to OpenClaw:
Memory organized in a hierarchical tree structure with natural language format, that enables structured knowledge organization, and efficient retrieval.
Memory curation capability that makes memory stateful.
Memory retrieval through a tiered system (cache → full-text → LLM search) that optimizes both speed and precision.
100% control over the memory: edit, update, and restructure memory at any time.
Portable memory on cloud. Sync memory into the cloud so it can be used by any agents, any setup, with ByteRover’s cloud-based platform. It comes with a web interface that supports version control and memory management.
You can run ByteRover with your choice of models/providers.
You can use ByteRover in combination with / separate OpenClaw’s existing memory system, and OpenClaw’s qmd, depending on your preference.
Get started now
ByteRover CLI 2.0 is available now.
👉 Install ByteRover CLI:
👉 Read OpenClaw x ByteRover documentation