Product Release
Architecture Deep Dive: ByteRover CLI 2.0 - Memory For Autonomous Agents
We are excited to launch ByteRover CLI 2.0 this week, as we expand our memory capabilities to support more autonomous agents such as OpenClaw.
We have already shared highlights of ByteRover’s new capabilities and how it works with OpenClaw. In our recently released benchmark, we have demonstrated that ByteRover’s core architecture, combining curation capabilities, a memory tree structure, and an agentic file-based retrieval engine that helps ByteRover retrieval accuracy, among the highest in the market, with an overall score of 92.2%.
In this blog, we will dive deeper into the architectures that have enabled this level of accuracy.

1- How Memory Is Organized: The Tree Structure and Files.
No external database. No cloud dependency. Just markdown files organized in a semantic hierarchy. The structure follows three levels: Domain → Topic → Subtopic.
Each level includes a context.md file that defines the node’s purpose, scope, and relationships. Every knowledge entry is stored as a standalone markdown file.
.brv/context-tree/ │ ├── market_analysis/ # Domain │ ├── context.md # Domain metadata (purpose,scope) │ ├── semiconductor_sector/ # Topic │ │ ├── context.md # Topic overview, key concepts │ │ ├── nvidia_earnings_q4_2025.md # Knowledge entry │ │ ├── supply_chain_dynamics.md # Knowledge entry │ │ └── geopolitical_risk/ # Subtopic │ │ ├── context.md # Subtopic focus │ │ └── china_export_controls.md # Knowledge entry │ └── energy_transition/ │ ├── context.md │ └── lithium_supply_forecast.md │ ├── trading_strategies/ │ ├── context.md │ ├── momentum/ │ │ ├── mean_reversion_signals.md │ │ └── earnings_drift_pattern.md │ └── risk_management/ │ └── position_sizing_rules.md │ ├── portfolio/ │ ├── context.md │ ├── allocation/ │ │ ├── current_holdings.md │ │ └── rebalancing_criteria.md │ └── client_preferences/ │ └── risk_tolerance_profile.md
Why Files, Not Database?
File is still the best abstraction so far for LLM (Cursor). For ByteRover, there are 3 things we look at:
First, version control.
The entire context tree is fully diffable, branchable, and mergeable. You can track exactly what an agent learned last week versus this week. Since each OpenClaw agent workspace is already a self-contained directory, the Context Tree integrates naturally with existing backup and synchronization workflows.
Second, transparency.
Every entry is human-readable. There are no opaque embedding vectors or black-box retrieval layers. When an agent makes a decision, whether planning a code refactor, drafting a content brief, or adjusting a trading strategy, ou can trace precisely what knowledge it used and why.
Third, zero infrastructure.
There is no vector database to provision and no embedding service to call. All knowledge lives directly inside the agent workspace, alongside persona files (AGENTS.md, USER.md) and skill configurations. A single directory contains everything an agent needs to operate.
2- Stateful memory curation
LLM Runs Code in a Sandbox to Curate Knowledge
The core idea is simple: give an LLM access to a computer and allow it to operate, rather than merely respond.
A computer provides two meta-capabilities that form the foundation of general task solving:
File management - reading, writing, and organizing data persistently across sessions
Code execution - writing and running arbitrary programs to transform, analyze, and act on information
Sandbox environment with well-defined "meta-capabilities" gives agent the freedom and the resources to come up with the best methods for the problems at hands, with exceptional generalization and scalability. In previous study, file management has been proven to be one of the 3 essential meta capability for AI agent in a sandbox environment (LLM-in-Sandbox research, 2026). At ByteRover, we divide that capability into 5 distinct operations that covers everything an agent needs to manage the context tree, regardless of which problem it might face, from de-dupication to conflict resolution.
Below is the sandbox architecture:
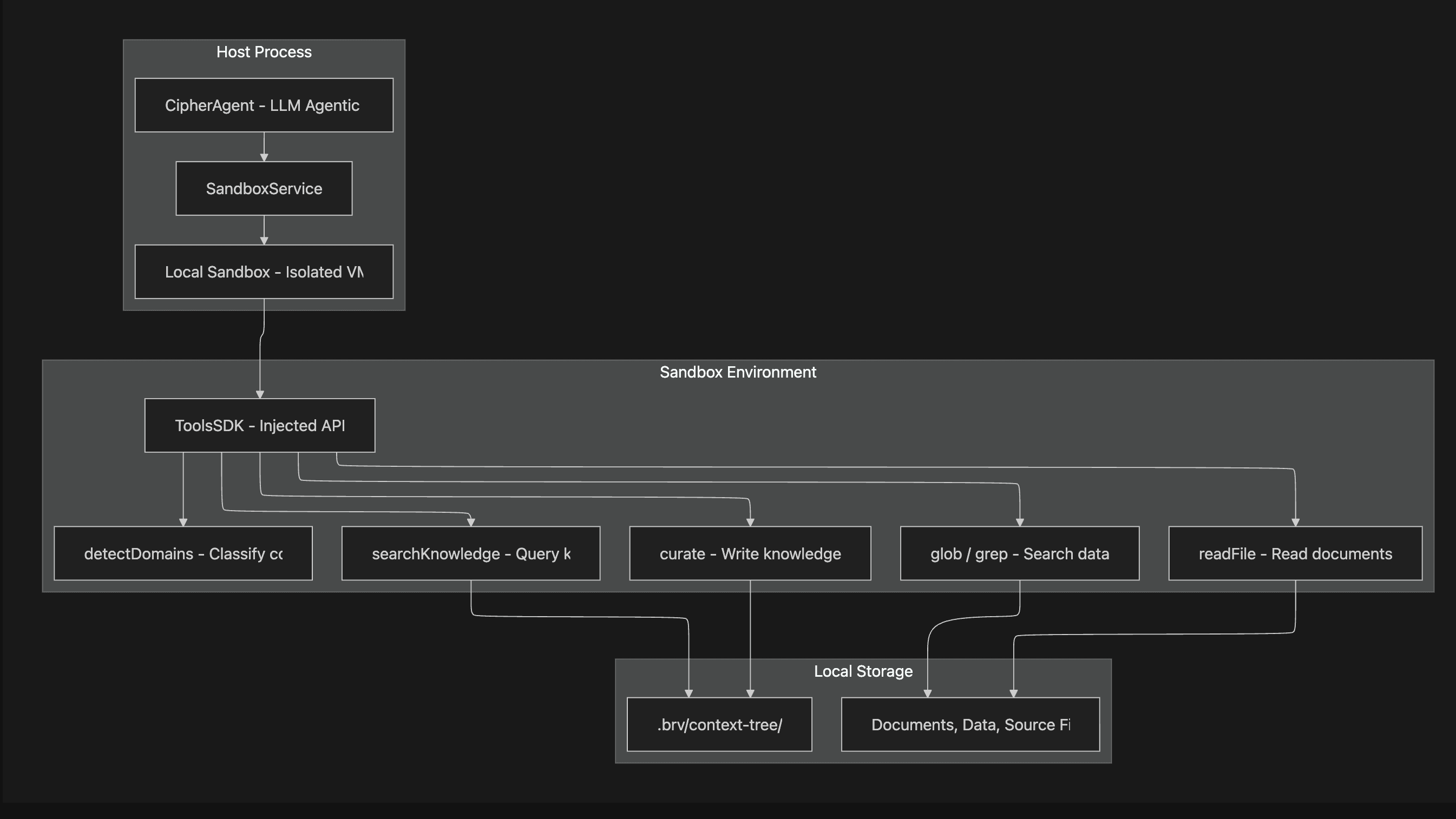
The ToolsSDK is the critical interface. It is injected into the sandbox, giving the LLM-generated code controlled access to the file system and knowledge operations, while preventing arbitrary system access:
// The ToolsSDK interface — what the LLM's code can call inside the sandbox interface ToolsSDK { curate(operations: CurateOperation[]): Promise<CurateResult> searchKnowledge(query: string): Promise<SearchKnowledgeResult> readFile(path: string): Promise<FileContent> glob(pattern: string): Promise<GlobResult> grep(pattern: string): Promise<SearchResult> detectDomains(domains: DetectDomainsInput[]): Promise<DetectDomainsResult> writeFile(path: string, content: string): Promise<WriteResult> listDirectory(path?: string): Promise<ListDirectoryResult> }
This is fundamentally different from embedding-based systems. The LLM understands what it is storing. It reads source documents, reasons about patterns and relationships, and then produces structured curate operations that place knowledge in the right domain, topic, and subtopic with proper cross-references. A traditional RAG system would chunk an earnings report into 500-token fragments and embed them. ByteRover's agent reads the report, extracts the insights , margin trends, guidance changes, competitive signals, and places them in the right location in the knowledge hierarchy with explicit links to related concepts.
Multi-turn stateful curation
Curation is not a single function call. It is a multi-step pipeline where an LLM agent analyzes context and produces structured knowledge. When an agent stores knowledge, it doesn't get a silent acknowledgment. It gets a detailed report of what was added, updated, merged, or failed, and why. If an operation fails, the LLM can reason about the failure and retry with a corrected approach. This is the stateful feedback loop- the system doesn't silently drop errors. It surfaces them as actionable information back to the agent.
The curation system supports five atomic operations in a multi-turn feedback loop.
Operation | Behavior |
|---|---|
| Create new knowledge entry. Auto-generates |
| Replace content of an existing entry |
| Add if new, update if exists (reduces pre-check overhead for the LLM) |
| Combine two entries intelligently, delete the source |
| Remove a single entry or an entire subtree |
The LLM gets feedback on every operation. Each curate call returns per-operation status:
// CurateOutput — the agent sees this after every curation attempt { applied: [ { type: 'UPSERT', path: 'trading_strategies/momentum', status: 'success', filePath: '.brv/context-tree/trading_strategies/momentum/earnings_drift_pattern.md' }, { type: 'MERGE', path: 'market_analysis/energy', status: 'failed', message: 'Source file not found: lithium_forecast_v1.md' }, ], summary: { added: 0, updated: 1, merged: 0, deleted: 0, failed: 1 } }
If an operation fails, the LLM can reason about the failure and retry with a corrected approach. This is the stateful feedback loop, the system doesn't silently drop errors. It surfaces them as actionable information back to the agent.
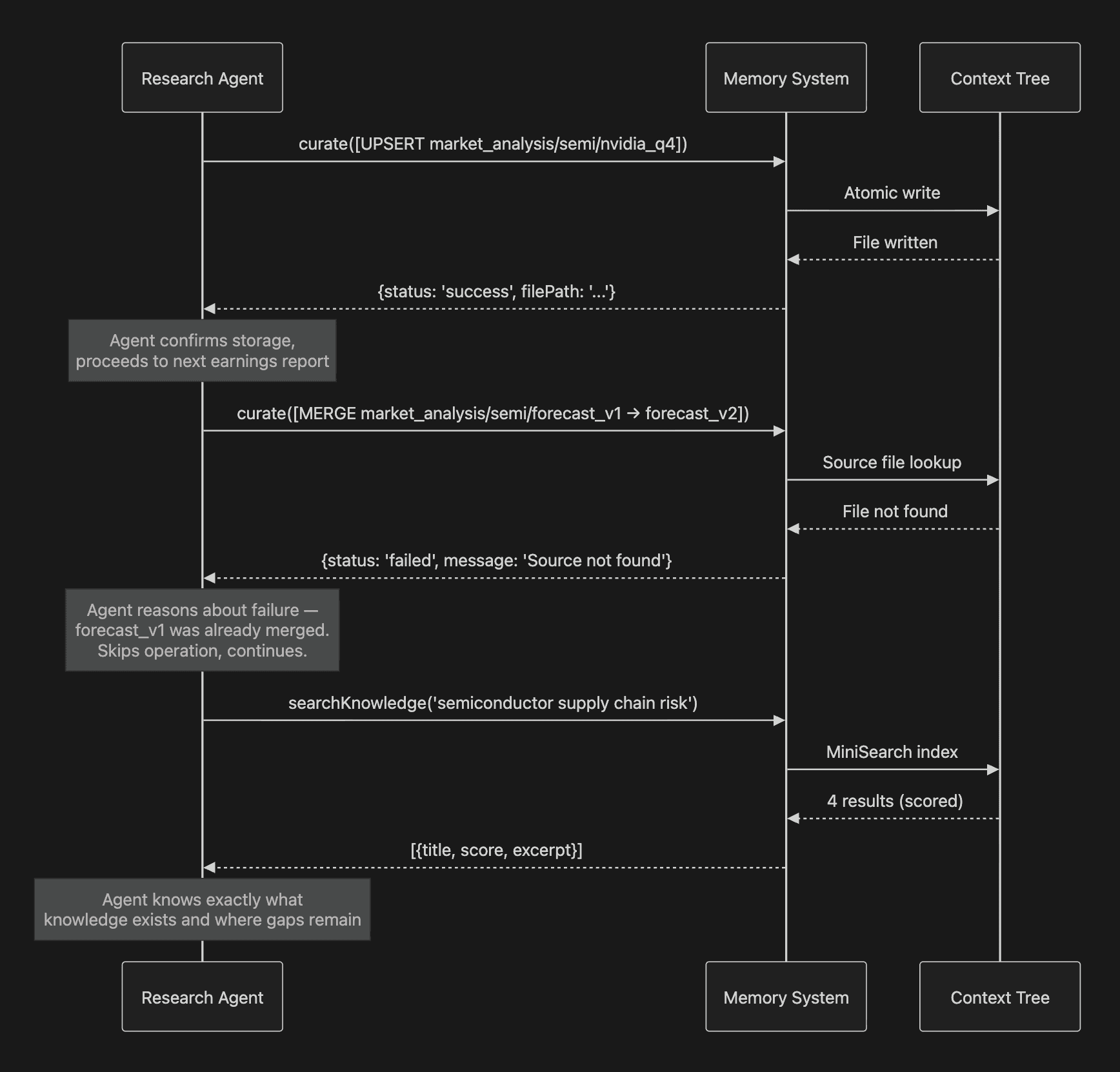
This feedback loop creates three properties that distinguish a memory assistant from a memory store:
Humans can audit what agents learned - every operation has a
reasonfield, a timestamp, and a status. A portfolio manager can review exactly what the research agent stored about a sector and why. A compliance team can trace the knowledge trail behind a trading decision.Agents can recover from failures - a failed MERGE doesn't corrupt state; the agent sees the error and adapts. If a market data source was unavailable, the agent knows the gap exists and can flag it or retry later. The memory system tells you what it doesn't know.
Continuity across sessions - when an agent resumes work after a crash, a timeout, or simply a new day, it can query the context tree to understand exactly where it left off. The state is in the files, not in the vanished context window.
Atomic Writes and Crash Safety
All file operations go through DirectoryManager.writeFileAtomic(). If the process crashes mid-write, the context tree remains consistent. No partial entries, no corrupted knowledge. For domains like trading where data integrity is non-negotiable, this matters.
3- Tiered retrieval pipeline > one-shot operation
The “retrieval task” for autonomous agent cannot just be one-shot operation (what is popular on the market) hoping to get “the best context” without any “intelligent reasoning”.
ByteRover uses a tiered response strategy that balances speed against depth: Cache lookup → full-text search → LLM-powered search, including LLM search, and Recursive LLM search.
For recursive LLM Search, key idea is to give LLM an environment to explore the context intelligently, and spawn sub LLMs to deal with each piece of context in a recursive manner. In this Recursive Language Model framework (RLM), each LLM can discover a more coherent, concise and natural piece of context, that is suitable for what it decides to need at each recursive step (cite). The result is less noise, less token consumed, better result (Alex L. Zhang, 2025). ByteRover context tree also provides the perfect structure for RLM, as it is modular, hierarchical and recursive by structure.
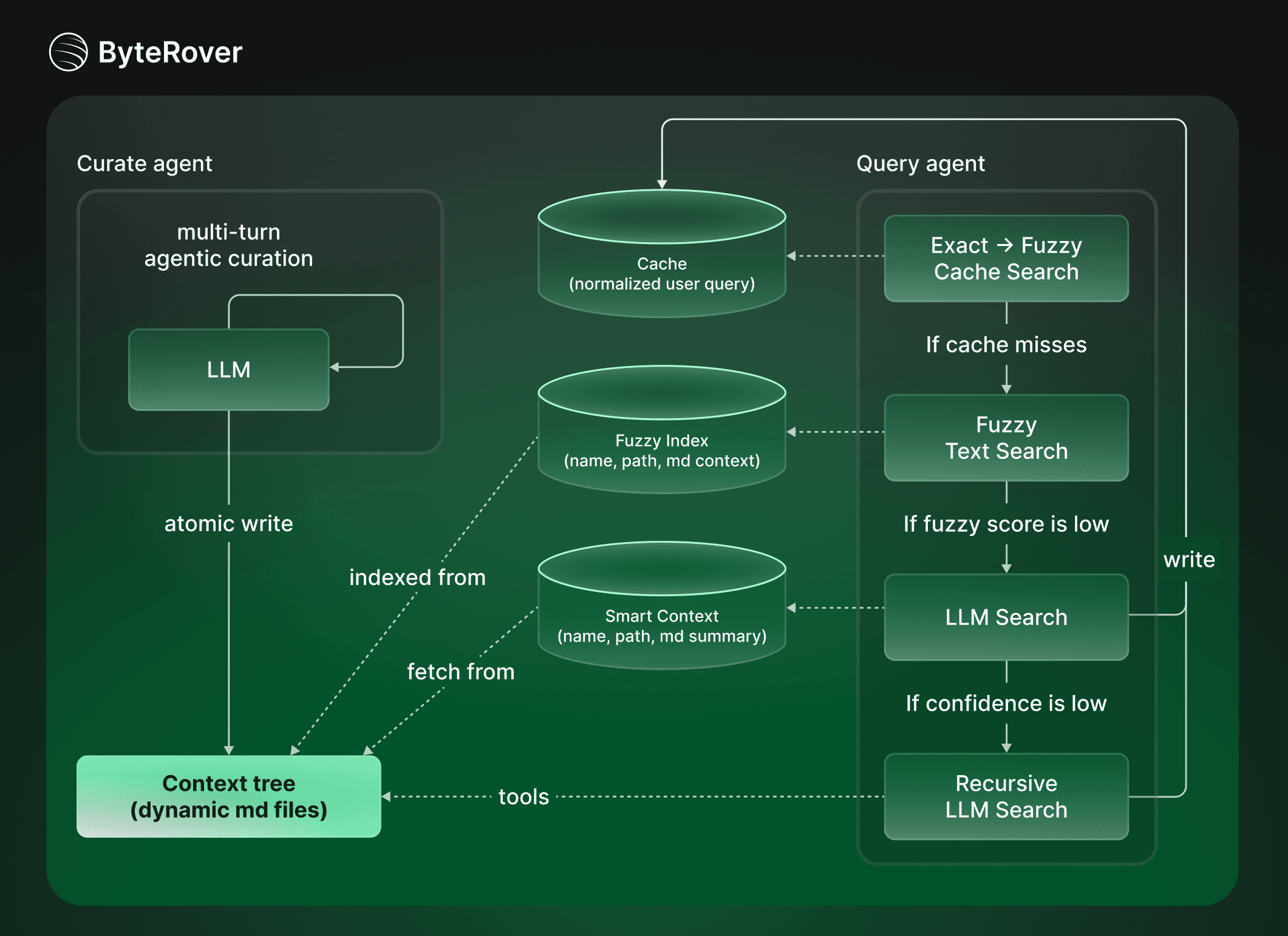
Most queries resolve at Tier 0-2 (under 100ms). Only novel or complex questions require an LLM call. This tiered approach matters in time-sensitive domains like trading, where you want sub-second access to stored knowledge and reserve expensive model calls for genuine reasoning tasks.
The search engine is MiniSearch - a lightweight full-text search library with fuzzy matching, prefix search, and configurable field boosting:
const MINISEARCH_OPTIONS = { fields: ['title', 'content', 'path'], idField: 'id', searchOptions: { boost: { path: 1.5, title: 3 }, // Titles and paths weighted for precision fuzzy: 0.2, // 80% character similarity threshold prefix: true, // Partial word matching }, storeFields: ['title', 'path'], }
A critical feature is Out-of-Domain (OOD) detection. When a query contains significant terms that don't match anything in the knowledge base, the system explicitly tells the agent: "this query appears outside the scope of stored knowledge." This prevents hallucinated answers from incomplete context - an essential property when agents are making financial decisions or presenting research to stakeholders.
4- Privacy, Control, and Model Flexibility as Structural Advantages
ByteRover's architecture makes three properties structural rather than optional:
Local-First by Design
The context tree is a local directory. The sandbox runs locally. The search index is in-process. The only external call is to the LLM provider, and even that is configurable.
For regulated industries - finance, healthcare, legal - this is not a nice-to-have. It is a compliance requirement. Your client data, your proprietary research, your trading signals never touch a third-party vector database or a cloud-hosted memory service. They live on your machine, under your control.
Model Agnosticism
ByteRover supports 17 providers out of the box, and any OpenAI-compatible endpoint, through a unified content generator interface.
Popular Providers:
Provider | Description |
|---|---|
byterover | Internal ByteRover protocol |
openrouter | 200+ models via aggregator |
anthropic | Claude (Opus, Sonnet, Haiku) |
openai | GPT-4.1, o-series |
Gemini via AI Studio | |
google-vertex | Gemini via Google Cloud Vertex AI |
xai | Grok models |
groq | Ultra-fast inference on open models |
mistral | Mistral Large, Codestral |
Extended Providers:
Provider | Description |
|---|---|
deepinfra | Affordable open-model inference |
cohere | Command R/R+ models |
togetherai | Open-source model inference |
perplexity | Web search-augmented inference |
cerebras | Hardware-accelerated inference |
vercel | Vercel AI-powered models |
openai-compatible | Any compatible endpoint (Ollama, LM Studio, vLLM, etc.) |
All providers pass through a Decorator Chain: RetryableContentGenerator → LoggingContentGenerator → AiSdkContentGenerator / Custom.
This is not just a convenience feature. It is a cost-performance lever you can tune per task:
Task Type | Recommended Approach | Why |
|---|---|---|
Complex curation (earnings analysis, strategy synthesis) | Frontier models (Claude, GPT-4) | Deep reasoning, nuanced judgment |
Routine queries ("What's our NVDA position?") | Fast/cheap models (Groq, Mistral) | Simple retrieval, speed matters |
Sensitive data (client portfolios, PII) | Local models (Ollama, LM Studio via OpenRouter) | Data never crosses a network boundary |
Bulk processing (100 reports overnight) | Mid-tier models (DeepSeek, Gemini Flash) | Cost-efficient at scale |
You choose the tradeoff per task, not per architecture. Switch between Claude and a local Llama model without changing a line of configuration beyond the provider name.
Conclusion
By grounding memory in a transparent, file-based context tree, ByteRover replaces opaque embeddings with auditable knowledge. By running LLMs inside a sandbox with file and code execution, it turns models from passive responders into operators that can read, reason, write, verify, and recover. And by combining stateful curation, atomic writes, and tiered retrieval, it delivers both reliability and speed without sacrificing control.
The result is not just better retrieval, it’s continuity. Knowledge persists across sessions, failures are visible and correctable, and every decision can be traced back to concrete files and explicit reasoning. This matters most in domains where correctness, provenance, and privacy are non-negotiable: trading, research, compliance-heavy environments, and any system where agents are expected to own their outputs.
Get started now
ByteRover CLI 2.0 is available now.
👉 Install ByteRover CLI:
curl -fsSL https://www.byterover.dev/install.sh | sh
Reference:
Cursor, 2026. Dynamic context discovery. Cursor. https://cursor.com/blog/dynamic-context-discovery
Cheng, D., Huang, S., Gu, Y., Song, H., Chen, G., Dong, L., Zhao, W. X., Wen, J.-R., & Wei, F. (2026). LLM-in-Sandbox elicits general agentic intelligence. arXiv. https://doi.org/10.48550/arXiv.2601.16206
Zhang, A. L. (2025, October 15). Recursive Language Models. Retrieved from https://alexzhang13.github.io/blog/2025/rlm/
1- How Memory Is Organized: The Tree Structure and Files.
No external database. No cloud dependency. Just markdown files organized in a semantic hierarchy. The structure follows three levels: Domain → Topic → Subtopic.
Each level includes a context.md file that defines the node’s purpose, scope, and relationships. Every knowledge entry is stored as a standalone markdown file.
.brv/context-tree/ │ ├── market_analysis/ # Domain │ ├── context.md # Domain metadata (purpose,scope) │ ├── semiconductor_sector/ # Topic │ │ ├── context.md # Topic overview, key concepts │ │ ├── nvidia_earnings_q4_2025.md # Knowledge entry │ │ ├── supply_chain_dynamics.md # Knowledge entry │ │ └── geopolitical_risk/ # Subtopic │ │ ├── context.md # Subtopic focus │ │ └── china_export_controls.md # Knowledge entry │ └── energy_transition/ │ ├── context.md │ └── lithium_supply_forecast.md │ ├── trading_strategies/ │ ├── context.md │ ├── momentum/ │ │ ├── mean_reversion_signals.md │ │ └── earnings_drift_pattern.md │ └── risk_management/ │ └── position_sizing_rules.md │ ├── portfolio/ │ ├── context.md │ ├── allocation/ │ │ ├── current_holdings.md │ │ └── rebalancing_criteria.md │ └── client_preferences/ │ └── risk_tolerance_profile.md
Why Files, Not Database?
File is still the best abstraction so far for LLM (Cursor). For ByteRover, there are 3 things we look at:
First, version control.
The entire context tree is fully diffable, branchable, and mergeable. You can track exactly what an agent learned last week versus this week. Since each OpenClaw agent workspace is already a self-contained directory, the Context Tree integrates naturally with existing backup and synchronization workflows.
Second, transparency.
Every entry is human-readable. There are no opaque embedding vectors or black-box retrieval layers. When an agent makes a decision, whether planning a code refactor, drafting a content brief, or adjusting a trading strategy, ou can trace precisely what knowledge it used and why.
Third, zero infrastructure.
There is no vector database to provision and no embedding service to call. All knowledge lives directly inside the agent workspace, alongside persona files (AGENTS.md, USER.md) and skill configurations. A single directory contains everything an agent needs to operate.
2- Stateful memory curation
LLM Runs Code in a Sandbox to Curate Knowledge
The core idea is simple: give an LLM access to a computer and allow it to operate, rather than merely respond.
A computer provides two meta-capabilities that form the foundation of general task solving:
File management - reading, writing, and organizing data persistently across sessions
Code execution - writing and running arbitrary programs to transform, analyze, and act on information
Sandbox environment with well-defined "meta-capabilities" gives agent the freedom and the resources to come up with the best methods for the problems at hands, with exceptional generalization and scalability. In previous study, file management has been proven to be one of the 3 essential meta capability for AI agent in a sandbox environment (LLM-in-Sandbox research, 2026). At ByteRover, we divide that capability into 5 distinct operations that covers everything an agent needs to manage the context tree, regardless of which problem it might face, from de-dupication to conflict resolution.
Below is the sandbox architecture:
The ToolsSDK is the critical interface. It is injected into the sandbox, giving the LLM-generated code controlled access to the file system and knowledge operations, while preventing arbitrary system access:
// The ToolsSDK interface — what the LLM's code can call inside the sandbox interface ToolsSDK { curate(operations: CurateOperation[]): Promise<CurateResult> searchKnowledge(query: string): Promise<SearchKnowledgeResult> readFile(path: string): Promise<FileContent> glob(pattern: string): Promise<GlobResult> grep(pattern: string): Promise<SearchResult> detectDomains(domains: DetectDomainsInput[]): Promise<DetectDomainsResult> writeFile(path: string, content: string): Promise<WriteResult> listDirectory(path?: string): Promise<ListDirectoryResult> }
This is fundamentally different from embedding-based systems. The LLM understands what it is storing. It reads source documents, reasons about patterns and relationships, and then produces structured curate operations that place knowledge in the right domain, topic, and subtopic with proper cross-references. A traditional RAG system would chunk an earnings report into 500-token fragments and embed them. ByteRover's agent reads the report, extracts the insights , margin trends, guidance changes, competitive signals, and places them in the right location in the knowledge hierarchy with explicit links to related concepts.
Multi-turn stateful curation
Curation is not a single function call. It is a multi-step pipeline where an LLM agent analyzes context and produces structured knowledge. When an agent stores knowledge, it doesn't get a silent acknowledgment. It gets a detailed report of what was added, updated, merged, or failed, and why. If an operation fails, the LLM can reason about the failure and retry with a corrected approach. This is the stateful feedback loop- the system doesn't silently drop errors. It surfaces them as actionable information back to the agent.
The curation system supports five atomic operations in a multi-turn feedback loop.
Operation | Behavior |
|---|---|
| Create new knowledge entry. Auto-generates |
| Replace content of an existing entry |
| Add if new, update if exists (reduces pre-check overhead for the LLM) |
| Combine two entries intelligently, delete the source |
| Remove a single entry or an entire subtree |
The LLM gets feedback on every operation. Each curate call returns per-operation status:
// CurateOutput — the agent sees this after every curation attempt { applied: [ { type: 'UPSERT', path: 'trading_strategies/momentum', status: 'success', filePath: '.brv/context-tree/trading_strategies/momentum/earnings_drift_pattern.md' }, { type: 'MERGE', path: 'market_analysis/energy', status: 'failed', message: 'Source file not found: lithium_forecast_v1.md' }, ], summary: { added: 0, updated: 1, merged: 0, deleted: 0, failed: 1 } }
If an operation fails, the LLM can reason about the failure and retry with a corrected approach. This is the stateful feedback loop, the system doesn't silently drop errors. It surfaces them as actionable information back to the agent.
This feedback loop creates three properties that distinguish a memory assistant from a memory store:
Humans can audit what agents learned - every operation has a
reasonfield, a timestamp, and a status. A portfolio manager can review exactly what the research agent stored about a sector and why. A compliance team can trace the knowledge trail behind a trading decision.Agents can recover from failures - a failed MERGE doesn't corrupt state; the agent sees the error and adapts. If a market data source was unavailable, the agent knows the gap exists and can flag it or retry later. The memory system tells you what it doesn't know.
Continuity across sessions - when an agent resumes work after a crash, a timeout, or simply a new day, it can query the context tree to understand exactly where it left off. The state is in the files, not in the vanished context window.
Atomic Writes and Crash Safety
All file operations go through DirectoryManager.writeFileAtomic(). If the process crashes mid-write, the context tree remains consistent. No partial entries, no corrupted knowledge. For domains like trading where data integrity is non-negotiable, this matters.
3- Tiered retrieval pipeline > one-shot operation
The “retrieval task” for autonomous agent cannot just be one-shot operation (what is popular on the market) hoping to get “the best context” without any “intelligent reasoning”.
ByteRover uses a tiered response strategy that balances speed against depth: Cache lookup → full-text search → LLM-powered search, including LLM search, and Recursive LLM search.
For recursive LLM Search, key idea is to give LLM an environment to explore the context intelligently, and spawn sub LLMs to deal with each piece of context in a recursive manner. In this Recursive Language Model framework (RLM), each LLM can discover a more coherent, concise and natural piece of context, that is suitable for what it decides to need at each recursive step (cite). The result is less noise, less token consumed, better result (Alex L. Zhang, 2025). ByteRover context tree also provides the perfect structure for RLM, as it is modular, hierarchical and recursive by structure.
Most queries resolve at Tier 0-2 (under 100ms). Only novel or complex questions require an LLM call. This tiered approach matters in time-sensitive domains like trading, where you want sub-second access to stored knowledge and reserve expensive model calls for genuine reasoning tasks.
The search engine is MiniSearch - a lightweight full-text search library with fuzzy matching, prefix search, and configurable field boosting:
const MINISEARCH_OPTIONS = { fields: ['title', 'content', 'path'], idField: 'id', searchOptions: { boost: { path: 1.5, title: 3 }, // Titles and paths weighted for precision fuzzy: 0.2, // 80% character similarity threshold prefix: true, // Partial word matching }, storeFields: ['title', 'path'], }
A critical feature is Out-of-Domain (OOD) detection. When a query contains significant terms that don't match anything in the knowledge base, the system explicitly tells the agent: "this query appears outside the scope of stored knowledge." This prevents hallucinated answers from incomplete context - an essential property when agents are making financial decisions or presenting research to stakeholders.
4- Privacy, Control, and Model Flexibility as Structural Advantages
ByteRover's architecture makes three properties structural rather than optional:
Local-First by Design
The context tree is a local directory. The sandbox runs locally. The search index is in-process. The only external call is to the LLM provider, and even that is configurable.
For regulated industries - finance, healthcare, legal - this is not a nice-to-have. It is a compliance requirement. Your client data, your proprietary research, your trading signals never touch a third-party vector database or a cloud-hosted memory service. They live on your machine, under your control.
Model Agnosticism
ByteRover supports 17 providers out of the box, and any OpenAI-compatible endpoint, through a unified content generator interface.
Popular Providers:
Provider | Description |
|---|---|
byterover | Internal ByteRover protocol |
openrouter | 200+ models via aggregator |
anthropic | Claude (Opus, Sonnet, Haiku) |
openai | GPT-4.1, o-series |
Gemini via AI Studio | |
google-vertex | Gemini via Google Cloud Vertex AI |
xai | Grok models |
groq | Ultra-fast inference on open models |
mistral | Mistral Large, Codestral |
Extended Providers:
Provider | Description |
|---|---|
deepinfra | Affordable open-model inference |
cohere | Command R/R+ models |
togetherai | Open-source model inference |
perplexity | Web search-augmented inference |
cerebras | Hardware-accelerated inference |
vercel | Vercel AI-powered models |
openai-compatible | Any compatible endpoint (Ollama, LM Studio, vLLM, etc.) |
All providers pass through a Decorator Chain: RetryableContentGenerator → LoggingContentGenerator → AiSdkContentGenerator / Custom.
This is not just a convenience feature. It is a cost-performance lever you can tune per task:
Task Type | Recommended Approach | Why |
|---|---|---|
Complex curation (earnings analysis, strategy synthesis) | Frontier models (Claude, GPT-4) | Deep reasoning, nuanced judgment |
Routine queries ("What's our NVDA position?") | Fast/cheap models (Groq, Mistral) | Simple retrieval, speed matters |
Sensitive data (client portfolios, PII) | Local models (Ollama, LM Studio via OpenRouter) | Data never crosses a network boundary |
Bulk processing (100 reports overnight) | Mid-tier models (DeepSeek, Gemini Flash) | Cost-efficient at scale |
You choose the tradeoff per task, not per architecture. Switch between Claude and a local Llama model without changing a line of configuration beyond the provider name.
Conclusion
By grounding memory in a transparent, file-based context tree, ByteRover replaces opaque embeddings with auditable knowledge. By running LLMs inside a sandbox with file and code execution, it turns models from passive responders into operators that can read, reason, write, verify, and recover. And by combining stateful curation, atomic writes, and tiered retrieval, it delivers both reliability and speed without sacrificing control.
The result is not just better retrieval, it’s continuity. Knowledge persists across sessions, failures are visible and correctable, and every decision can be traced back to concrete files and explicit reasoning. This matters most in domains where correctness, provenance, and privacy are non-negotiable: trading, research, compliance-heavy environments, and any system where agents are expected to own their outputs.
Get started now
ByteRover CLI 2.0 is available now.
👉 Install ByteRover CLI:
curl -fsSL https://www.byterover.dev/install.sh | sh
Reference:
Cursor, 2026. Dynamic context discovery. Cursor. https://cursor.com/blog/dynamic-context-discovery
Cheng, D., Huang, S., Gu, Y., Song, H., Chen, G., Dong, L., Zhao, W. X., Wen, J.-R., & Wei, F. (2026). LLM-in-Sandbox elicits general agentic intelligence. arXiv. https://doi.org/10.48550/arXiv.2601.16206
Zhang, A. L. (2025, October 15). Recursive Language Models. Retrieved from https://alexzhang13.github.io/blog/2025/rlm/
1- How Memory Is Organized: The Tree Structure and Files.
No external database. No cloud dependency. Just markdown files organized in a semantic hierarchy. The structure follows three levels: Domain → Topic → Subtopic.
Each level includes a context.md file that defines the node’s purpose, scope, and relationships. Every knowledge entry is stored as a standalone markdown file.
.brv/context-tree/ │ ├── market_analysis/ # Domain │ ├── context.md # Domain metadata (purpose,scope) │ ├── semiconductor_sector/ # Topic │ │ ├── context.md # Topic overview, key concepts │ │ ├── nvidia_earnings_q4_2025.md # Knowledge entry │ │ ├── supply_chain_dynamics.md # Knowledge entry │ │ └── geopolitical_risk/ # Subtopic │ │ ├── context.md # Subtopic focus │ │ └── china_export_controls.md # Knowledge entry │ └── energy_transition/ │ ├── context.md │ └── lithium_supply_forecast.md │ ├── trading_strategies/ │ ├── context.md │ ├── momentum/ │ │ ├── mean_reversion_signals.md │ │ └── earnings_drift_pattern.md │ └── risk_management/ │ └── position_sizing_rules.md │ ├── portfolio/ │ ├── context.md │ ├── allocation/ │ │ ├── current_holdings.md │ │ └── rebalancing_criteria.md │ └── client_preferences/ │ └── risk_tolerance_profile.md
Why Files, Not Database?
File is still the best abstraction so far for LLM (Cursor). For ByteRover, there are 3 things we look at:
First, version control.
The entire context tree is fully diffable, branchable, and mergeable. You can track exactly what an agent learned last week versus this week. Since each OpenClaw agent workspace is already a self-contained directory, the Context Tree integrates naturally with existing backup and synchronization workflows.
Second, transparency.
Every entry is human-readable. There are no opaque embedding vectors or black-box retrieval layers. When an agent makes a decision, whether planning a code refactor, drafting a content brief, or adjusting a trading strategy, ou can trace precisely what knowledge it used and why.
Third, zero infrastructure.
There is no vector database to provision and no embedding service to call. All knowledge lives directly inside the agent workspace, alongside persona files (AGENTS.md, USER.md) and skill configurations. A single directory contains everything an agent needs to operate.
2- Stateful memory curation
LLM Runs Code in a Sandbox to Curate Knowledge
The core idea is simple: give an LLM access to a computer and allow it to operate, rather than merely respond.
A computer provides two meta-capabilities that form the foundation of general task solving:
File management - reading, writing, and organizing data persistently across sessions
Code execution - writing and running arbitrary programs to transform, analyze, and act on information
Sandbox environment with well-defined "meta-capabilities" gives agent the freedom and the resources to come up with the best methods for the problems at hands, with exceptional generalization and scalability. In previous study, file management has been proven to be one of the 3 essential meta capability for AI agent in a sandbox environment (LLM-in-Sandbox research, 2026). At ByteRover, we divide that capability into 5 distinct operations that covers everything an agent needs to manage the context tree, regardless of which problem it might face, from de-dupication to conflict resolution.
Below is the sandbox architecture:
The ToolsSDK is the critical interface. It is injected into the sandbox, giving the LLM-generated code controlled access to the file system and knowledge operations, while preventing arbitrary system access:
// The ToolsSDK interface — what the LLM's code can call inside the sandbox interface ToolsSDK { curate(operations: CurateOperation[]): Promise<CurateResult> searchKnowledge(query: string): Promise<SearchKnowledgeResult> readFile(path: string): Promise<FileContent> glob(pattern: string): Promise<GlobResult> grep(pattern: string): Promise<SearchResult> detectDomains(domains: DetectDomainsInput[]): Promise<DetectDomainsResult> writeFile(path: string, content: string): Promise<WriteResult> listDirectory(path?: string): Promise<ListDirectoryResult> }
This is fundamentally different from embedding-based systems. The LLM understands what it is storing. It reads source documents, reasons about patterns and relationships, and then produces structured curate operations that place knowledge in the right domain, topic, and subtopic with proper cross-references. A traditional RAG system would chunk an earnings report into 500-token fragments and embed them. ByteRover's agent reads the report, extracts the insights , margin trends, guidance changes, competitive signals, and places them in the right location in the knowledge hierarchy with explicit links to related concepts.
Multi-turn stateful curation
Curation is not a single function call. It is a multi-step pipeline where an LLM agent analyzes context and produces structured knowledge. When an agent stores knowledge, it doesn't get a silent acknowledgment. It gets a detailed report of what was added, updated, merged, or failed, and why. If an operation fails, the LLM can reason about the failure and retry with a corrected approach. This is the stateful feedback loop- the system doesn't silently drop errors. It surfaces them as actionable information back to the agent.
The curation system supports five atomic operations in a multi-turn feedback loop.
Operation | Behavior |
|---|---|
| Create new knowledge entry. Auto-generates |
| Replace content of an existing entry |
| Add if new, update if exists (reduces pre-check overhead for the LLM) |
| Combine two entries intelligently, delete the source |
| Remove a single entry or an entire subtree |
The LLM gets feedback on every operation. Each curate call returns per-operation status:
// CurateOutput — the agent sees this after every curation attempt { applied: [ { type: 'UPSERT', path: 'trading_strategies/momentum', status: 'success', filePath: '.brv/context-tree/trading_strategies/momentum/earnings_drift_pattern.md' }, { type: 'MERGE', path: 'market_analysis/energy', status: 'failed', message: 'Source file not found: lithium_forecast_v1.md' }, ], summary: { added: 0, updated: 1, merged: 0, deleted: 0, failed: 1 } }
If an operation fails, the LLM can reason about the failure and retry with a corrected approach. This is the stateful feedback loop, the system doesn't silently drop errors. It surfaces them as actionable information back to the agent.
This feedback loop creates three properties that distinguish a memory assistant from a memory store:
Humans can audit what agents learned - every operation has a
reasonfield, a timestamp, and a status. A portfolio manager can review exactly what the research agent stored about a sector and why. A compliance team can trace the knowledge trail behind a trading decision.Agents can recover from failures - a failed MERGE doesn't corrupt state; the agent sees the error and adapts. If a market data source was unavailable, the agent knows the gap exists and can flag it or retry later. The memory system tells you what it doesn't know.
Continuity across sessions - when an agent resumes work after a crash, a timeout, or simply a new day, it can query the context tree to understand exactly where it left off. The state is in the files, not in the vanished context window.
Atomic Writes and Crash Safety
All file operations go through DirectoryManager.writeFileAtomic(). If the process crashes mid-write, the context tree remains consistent. No partial entries, no corrupted knowledge. For domains like trading where data integrity is non-negotiable, this matters.
3- Tiered retrieval pipeline > one-shot operation
The “retrieval task” for autonomous agent cannot just be one-shot operation (what is popular on the market) hoping to get “the best context” without any “intelligent reasoning”.
ByteRover uses a tiered response strategy that balances speed against depth: Cache lookup → full-text search → LLM-powered search, including LLM search, and Recursive LLM search.
For recursive LLM Search, key idea is to give LLM an environment to explore the context intelligently, and spawn sub LLMs to deal with each piece of context in a recursive manner. In this Recursive Language Model framework (RLM), each LLM can discover a more coherent, concise and natural piece of context, that is suitable for what it decides to need at each recursive step (cite). The result is less noise, less token consumed, better result (Alex L. Zhang, 2025). ByteRover context tree also provides the perfect structure for RLM, as it is modular, hierarchical and recursive by structure.
Most queries resolve at Tier 0-2 (under 100ms). Only novel or complex questions require an LLM call. This tiered approach matters in time-sensitive domains like trading, where you want sub-second access to stored knowledge and reserve expensive model calls for genuine reasoning tasks.
The search engine is MiniSearch - a lightweight full-text search library with fuzzy matching, prefix search, and configurable field boosting:
const MINISEARCH_OPTIONS = { fields: ['title', 'content', 'path'], idField: 'id', searchOptions: { boost: { path: 1.5, title: 3 }, // Titles and paths weighted for precision fuzzy: 0.2, // 80% character similarity threshold prefix: true, // Partial word matching }, storeFields: ['title', 'path'], }
A critical feature is Out-of-Domain (OOD) detection. When a query contains significant terms that don't match anything in the knowledge base, the system explicitly tells the agent: "this query appears outside the scope of stored knowledge." This prevents hallucinated answers from incomplete context - an essential property when agents are making financial decisions or presenting research to stakeholders.
4- Privacy, Control, and Model Flexibility as Structural Advantages
ByteRover's architecture makes three properties structural rather than optional:
Local-First by Design
The context tree is a local directory. The sandbox runs locally. The search index is in-process. The only external call is to the LLM provider, and even that is configurable.
For regulated industries - finance, healthcare, legal - this is not a nice-to-have. It is a compliance requirement. Your client data, your proprietary research, your trading signals never touch a third-party vector database or a cloud-hosted memory service. They live on your machine, under your control.
Model Agnosticism
ByteRover supports 17 providers out of the box, and any OpenAI-compatible endpoint, through a unified content generator interface.
Popular Providers:
Provider | Description |
|---|---|
byterover | Internal ByteRover protocol |
openrouter | 200+ models via aggregator |
anthropic | Claude (Opus, Sonnet, Haiku) |
openai | GPT-4.1, o-series |
Gemini via AI Studio | |
google-vertex | Gemini via Google Cloud Vertex AI |
xai | Grok models |
groq | Ultra-fast inference on open models |
mistral | Mistral Large, Codestral |
Extended Providers:
Provider | Description |
|---|---|
deepinfra | Affordable open-model inference |
cohere | Command R/R+ models |
togetherai | Open-source model inference |
perplexity | Web search-augmented inference |
cerebras | Hardware-accelerated inference |
vercel | Vercel AI-powered models |
openai-compatible | Any compatible endpoint (Ollama, LM Studio, vLLM, etc.) |
All providers pass through a Decorator Chain: RetryableContentGenerator → LoggingContentGenerator → AiSdkContentGenerator / Custom.
This is not just a convenience feature. It is a cost-performance lever you can tune per task:
Task Type | Recommended Approach | Why |
|---|---|---|
Complex curation (earnings analysis, strategy synthesis) | Frontier models (Claude, GPT-4) | Deep reasoning, nuanced judgment |
Routine queries ("What's our NVDA position?") | Fast/cheap models (Groq, Mistral) | Simple retrieval, speed matters |
Sensitive data (client portfolios, PII) | Local models (Ollama, LM Studio via OpenRouter) | Data never crosses a network boundary |
Bulk processing (100 reports overnight) | Mid-tier models (DeepSeek, Gemini Flash) | Cost-efficient at scale |
You choose the tradeoff per task, not per architecture. Switch between Claude and a local Llama model without changing a line of configuration beyond the provider name.
Conclusion
By grounding memory in a transparent, file-based context tree, ByteRover replaces opaque embeddings with auditable knowledge. By running LLMs inside a sandbox with file and code execution, it turns models from passive responders into operators that can read, reason, write, verify, and recover. And by combining stateful curation, atomic writes, and tiered retrieval, it delivers both reliability and speed without sacrificing control.
The result is not just better retrieval, it’s continuity. Knowledge persists across sessions, failures are visible and correctable, and every decision can be traced back to concrete files and explicit reasoning. This matters most in domains where correctness, provenance, and privacy are non-negotiable: trading, research, compliance-heavy environments, and any system where agents are expected to own their outputs.
Get started now
ByteRover CLI 2.0 is available now.
👉 Install ByteRover CLI:
curl -fsSL https://www.byterover.dev/install.sh | sh
Reference:
Cursor, 2026. Dynamic context discovery. Cursor. https://cursor.com/blog/dynamic-context-discovery
Cheng, D., Huang, S., Gu, Y., Song, H., Chen, G., Dong, L., Zhao, W. X., Wen, J.-R., & Wei, F. (2026). LLM-in-Sandbox elicits general agentic intelligence. arXiv. https://doi.org/10.48550/arXiv.2601.16206
Zhang, A. L. (2025, October 15). Recursive Language Models. Retrieved from https://alexzhang13.github.io/blog/2025/rlm/