Article
Stop Solving the Same Bug Twice: Building a Payment Service with Claude Code
Recurring production bugs are rarely a skills problem. More often, they are a context problem. Teams fix an issue once, only to fix the same issue again months later because the original reasoning, trade-offs, and constraints were never preserved.
This challenge becomes more visible with AI coding agents such as Claude Code. Claude can read code, but it does not retain memory across sessions. When context is spread across markdown files, tickets, Slack threads, and past incidents, the agent has to reconstruct the system from scratch each time it starts a new task.
Data from more than 200 engineering teams shows that developers lose 1–2 hours per day restoring context after interruptions. Claude faces a similar burden: every new prompt forces it to re-scan files, re-infer behavior, and guess which past decisions still matter. The result is wasted tokens, shallow reasoning, and repeated mistakes.

The Problem: Static Context Breaks the Workflow
Consider a payment service with a recurring production bug that causes duplicate charges when a transaction fails. Over the past six months, the same issue has surfaced three times.
Each incident follows a familiar and inefficient pattern:
A different engineer picks up the ticket.
They start a new Claude Code session with no prior context.
The agent proposes fixes that were already tested and rejected in previous incidents.
Eventually, one fix works. However, the reasoning behind it disappears as soon as the session ends.
On the surface, the repository looks healthy. The code is clean, and the README is current. But the most valuable context is missing. The incident analysis explaining why the logic failed often lives in Google Docs, Slack threads, or ticket comments. These are places the agent cannot automatically access.
When the bug reappears months later, Claude has no visibility into that history. It does not know which approaches failed, what constraints were discovered, or which safety rules were introduced. Unless an engineer manually copies that information into the prompt, the agent is forced to reconstruct the system from scratch.
This leads to predictable problems:
Repetitive work: Claude suggests fixes that already failed.
Safety risks: The agent violates guardrails established during earlier incidents.
Inconsistent reasoning: The same bug is analyzed differently each time.
The issue is not markdown files or documentation quality. The real problem is that context is static and manual. Because the agent cannot automatically retrieve past learnings, incident knowledge remains siloed, and every new session starts from a blank slate.
The Goal: Persistent Context With Zero Friction
The goal is to ensure future Claude Code sessions do not start from zero. Instead, they should immediately understand:
Root cause: What actually triggered the bug previously.
Decision history: Which fixes were attempted, why they failed, and which solution was approved.
Safety rails: The constraints that must not be violated during changes or rollouts.
Crucially, this should happen without engineers manually pasting context into every prompt. The system should surface the right history automatically.
This guide shows how to convert “tribal knowledge” into a persistent, agent-readable memory layer that lives alongside your codebase.
What We Will Build
By the end of this tutorial, you will have a working Memory Layer for a real application:
The target: A live FastAPI project hosted on GitHub.
The baseline: A demonstration of Claude failing when relying only on static markdown.
The solution: Structured incident knowledge curated and queried dynamically by ByteRover.
The result: A workflow where Claude autonomously retrieves project history and ships a correct fix on the first attempt.
Prerequisites
To follow along, ensure your environment is ready:
ByteRover CLI (Installed & Authenticated)
Claude Code (Connected to ByteRover)
Git (Installed)
Basic familiarity with Claude Code commands
Note: This guide focuses on the context workflow. We assume you have the tools installed and are ready to run commands.
The Scenario: A Flawed Payment Service
We will use a lightweight FastAPI service to simulate a real-world failure.
The App: A payment gateway that handles charges, refunds, and rollbacks using in-memory state.
The Bug: An intentional race condition in the rollback logic that causes duplicate charges.
The Code: Available in this public GitHub repository.
Step 1: The Baseline - Claude with Markdown Only
First, we ask Claude Code to analyze the system and fix the rollback bug using only the raw codebase and static markdown documentation.
The Experiment
When you run the prompt, Claude follows a typical stateless workflow:
Ingests the visible codebase available in the session.
Infers execution paths from syntax and local references.
Proposes a fix based on general engineering best practices.
Explains its reasoning within that single session.
From Claude’s perspective, everything it knows exists only inside the current prompt window.
The Failure Mode
If you open a new terminal a week later and run the same prompt again, the outcome will often differ. Claude may:
Provide a different explanation of the root cause.
Suggest a contradictory implementation.
Miss edge cases it previously identified.
Even when the code has not changed, the reasoning does.
Why This Happens
Claude is stateless across sessions. Once the session ends, its working context disappears.
Even if your repository contains extensive markdown documentation, Claude still operates on static context. It cannot determine which files represent historical decisions, rejected fixes, or incident constraints unless a human explicitly surfaces them in the prompt.
The bottleneck is not the markdown format itself. It is the manual and static retrieval of knowledge. Because context does not persist across sessions, every fix Claude produces is effectively a first draft rather than an informed continuation of past work.
Step 2: Initialize the Project with ByteRover
Run the initialization command in your project root:
brv init
This generates the configuration file that serves as the contract between your repository and Claude Code. It defines the rules for context retrieval, ensuring the agent knows exactly where to look for project history before it writes a single line of code.
Step 3: Automate Context Discovery
Instead of manually writing documentation, we will delegate the heavy lifting to the agent.
Open a new terminal and run the following prompt. This instructs Claude to read the code and use ByteRover to generate a structured "mental map" of the system.
Prompt: “First read the entire codebase. Then use the brv curate command to infer what the system does from code alone, identify entry points, main execution paths, shared state, and assumptions, and write concise markdown documentation, without fixing or changing the code.”
By running brv curate, you didn't just ask Claude to read files but you created a persistent knowledge layer. ByteRover analyzed the raw syntax to map the system's logic, creating a baseline of context that will be available to every future agent session.
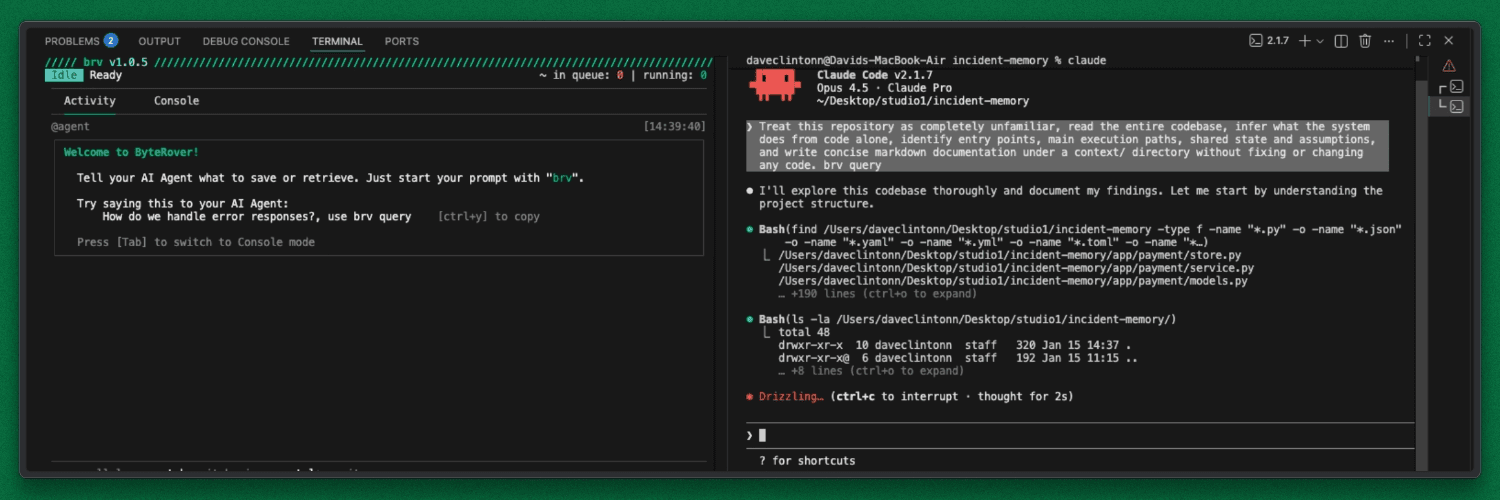
The Output: A Structured System Map
Claude Code executes the command and generates structured documentation covering:
System Architecture: High-level purpose and architectural boundaries.
Execution Flow: Primary entry points and API contract behavior.
State Management: How shared state is mutated (and where the risks lie).
Failure Analysis: Identification of known bugs and regression risks.
Reproduction: Exact steps to trigger the demo failure.
Step 4: Sync the Knowledge to ByteRover
Once discovery is completed, sync the generated context by running /push in the console tab of ByteRover.
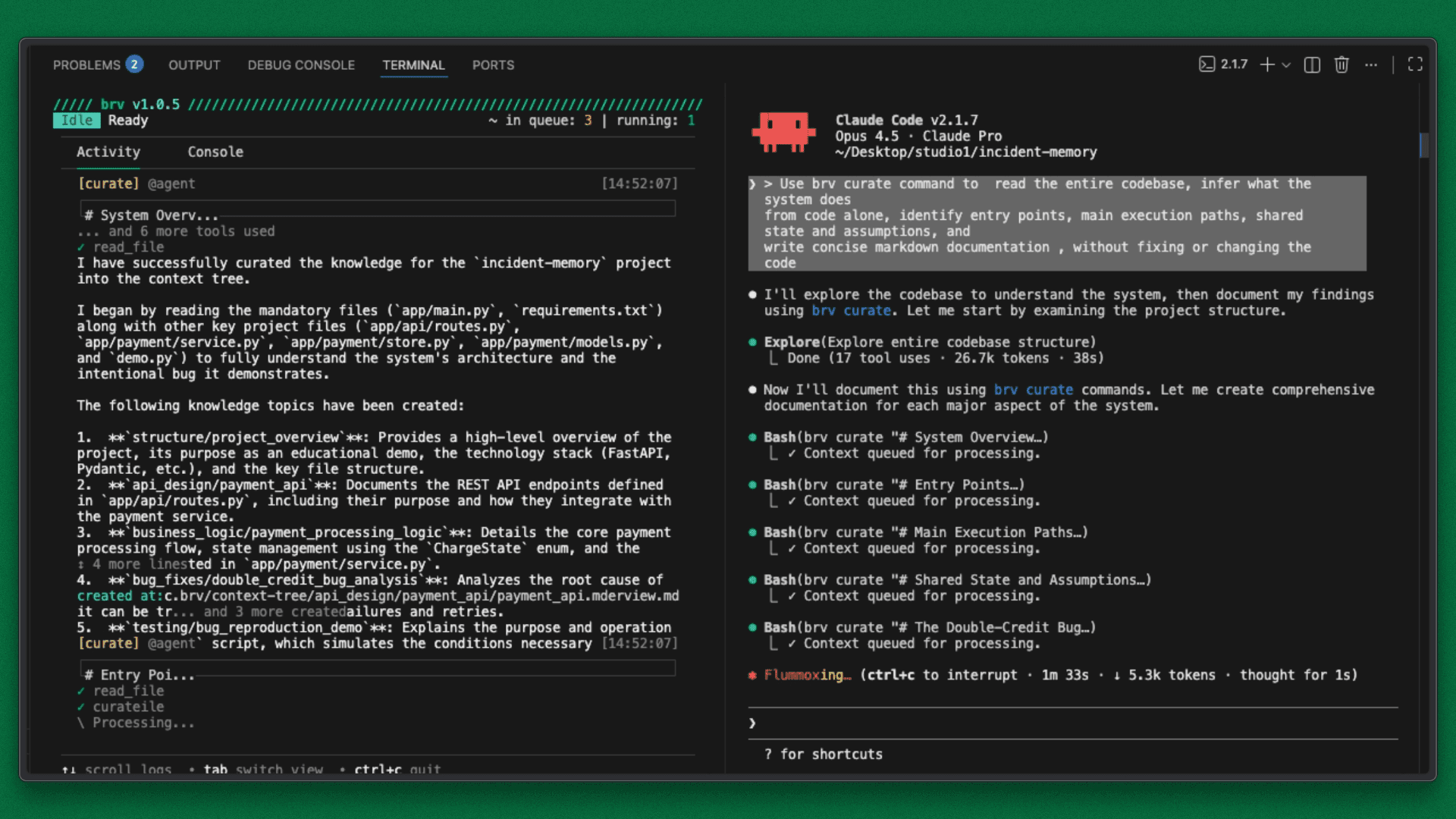
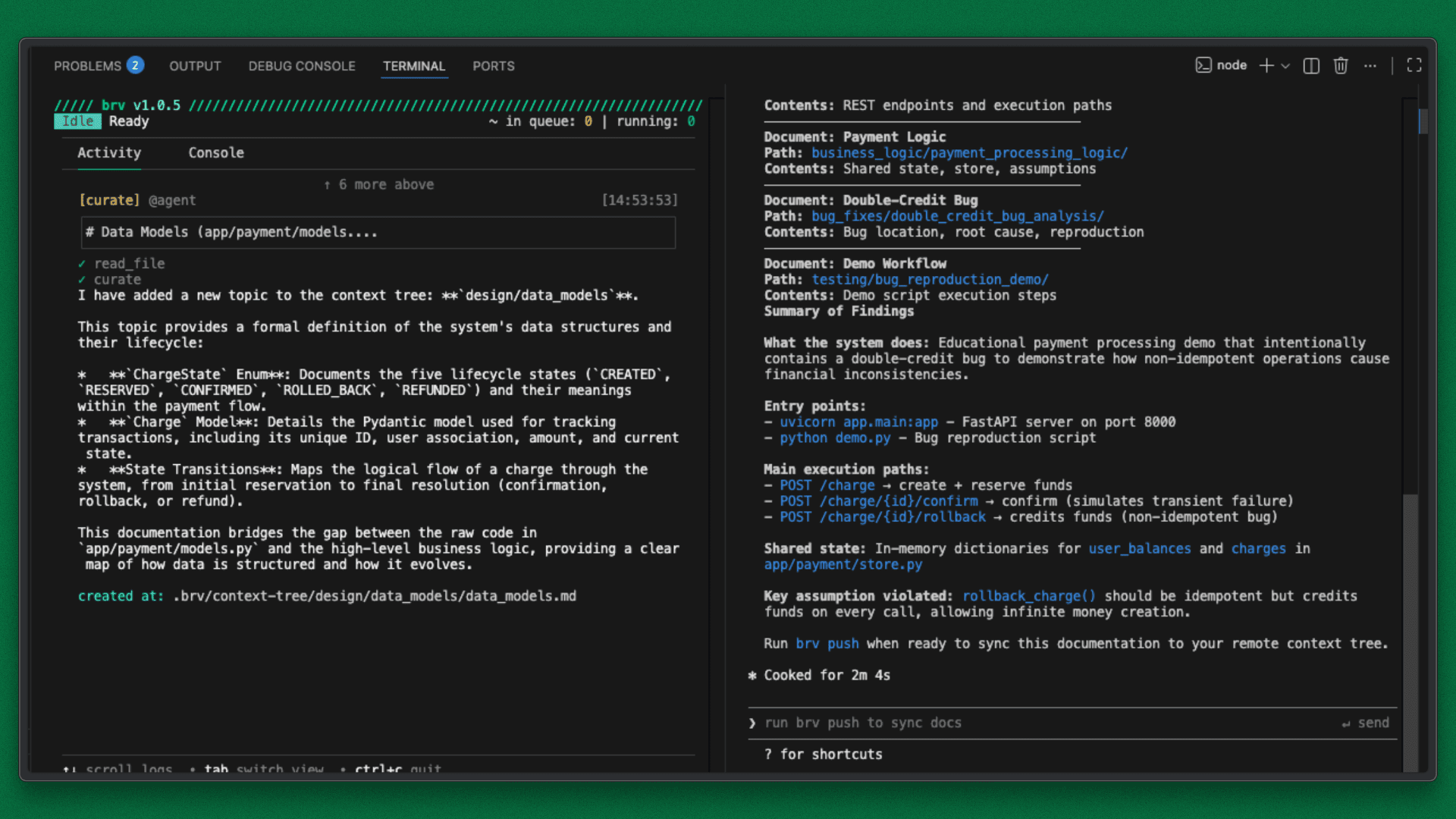
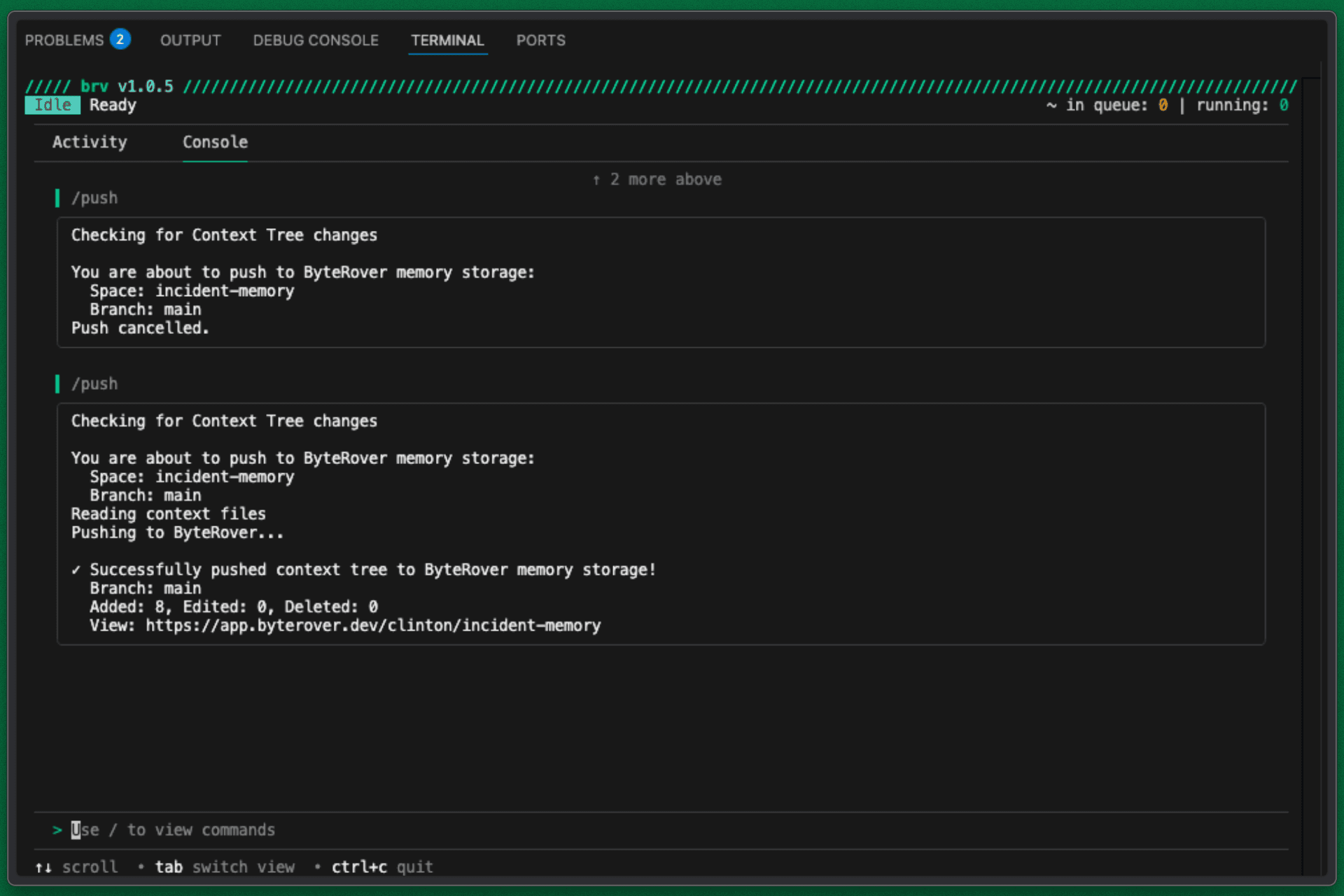
Sync to ByteRover Terminal Output
This commits the system understanding to ByteRover, making it instantly queryable for all future sessions.
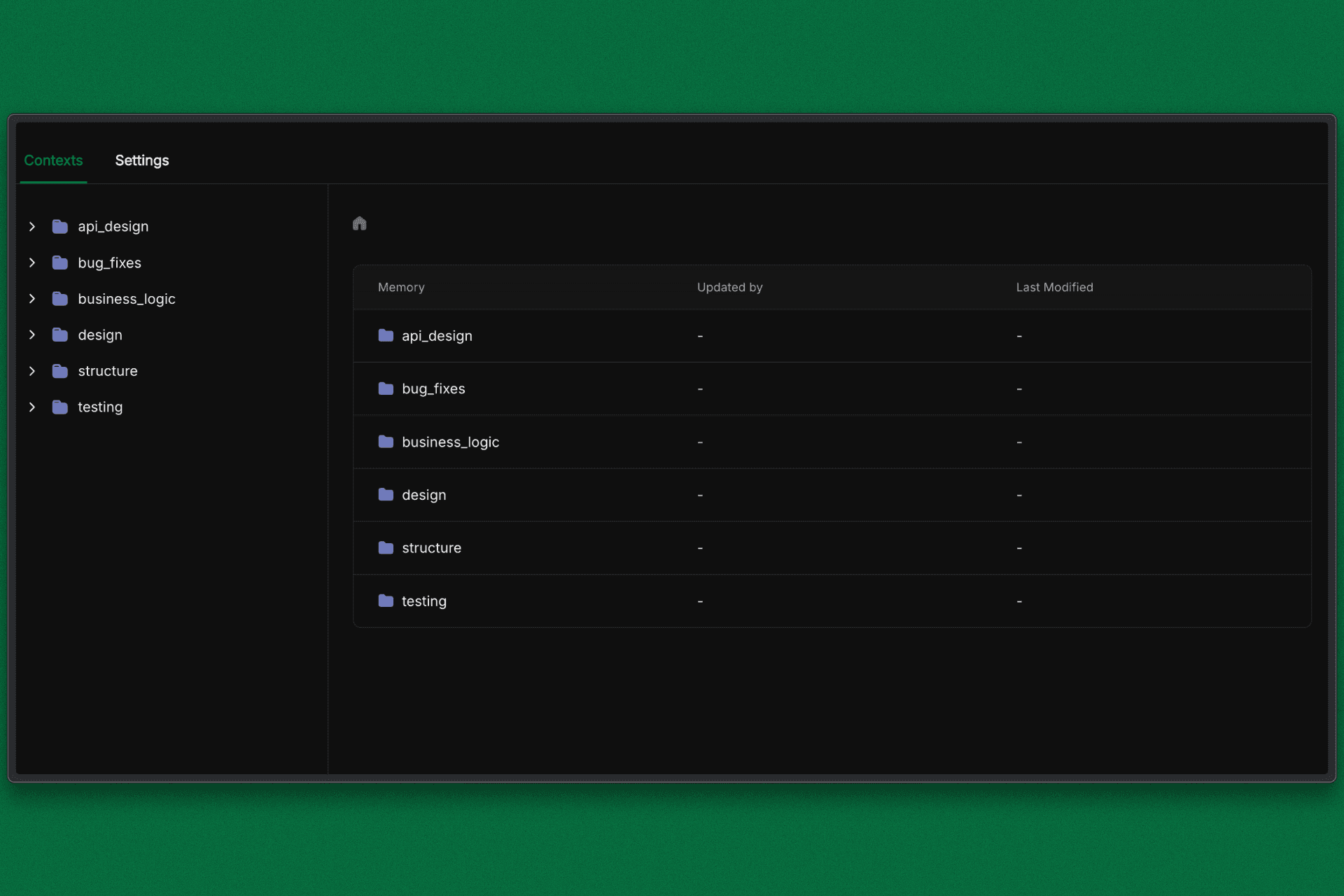
ByteRover Dashboard for First Knowledge Base
Step 5: Execute the Context-Aware Fix
With the knowledge layer established, we can now task Claude with the repair. Unlike the first attempt, the agent is no longer guessing but it is referencing the structural map and constraints we just defined.
Run the following command to initiate the fix:
brv query "Fix the double-credit rollback bug. Ensure the fix is idempotent, explain the race condition, and update the rollout documentation."
Why this is different:
By using brv query, we are not just chatting with the LLM. We are injecting the curated system context directly into the prompt pipeline. This ensures the workflow is token-efficient (no need to paste huge files) and historically accurate.
The Outcome:
Because Claude is now context-aware, it executes a precise sequence of actions:
Root Cause Analysis: It explicitly links the failure to the race condition identified in the system map.
Idempotency Implementation: It applies a state guard to prevent the specific duplicate charge vector.
Regression Testing: It validates the fix against the known failure mode.
Knowledge Capture: It automatically updates the markdown documentation to reflect the new architecture, ensuring the next developer understands the change.
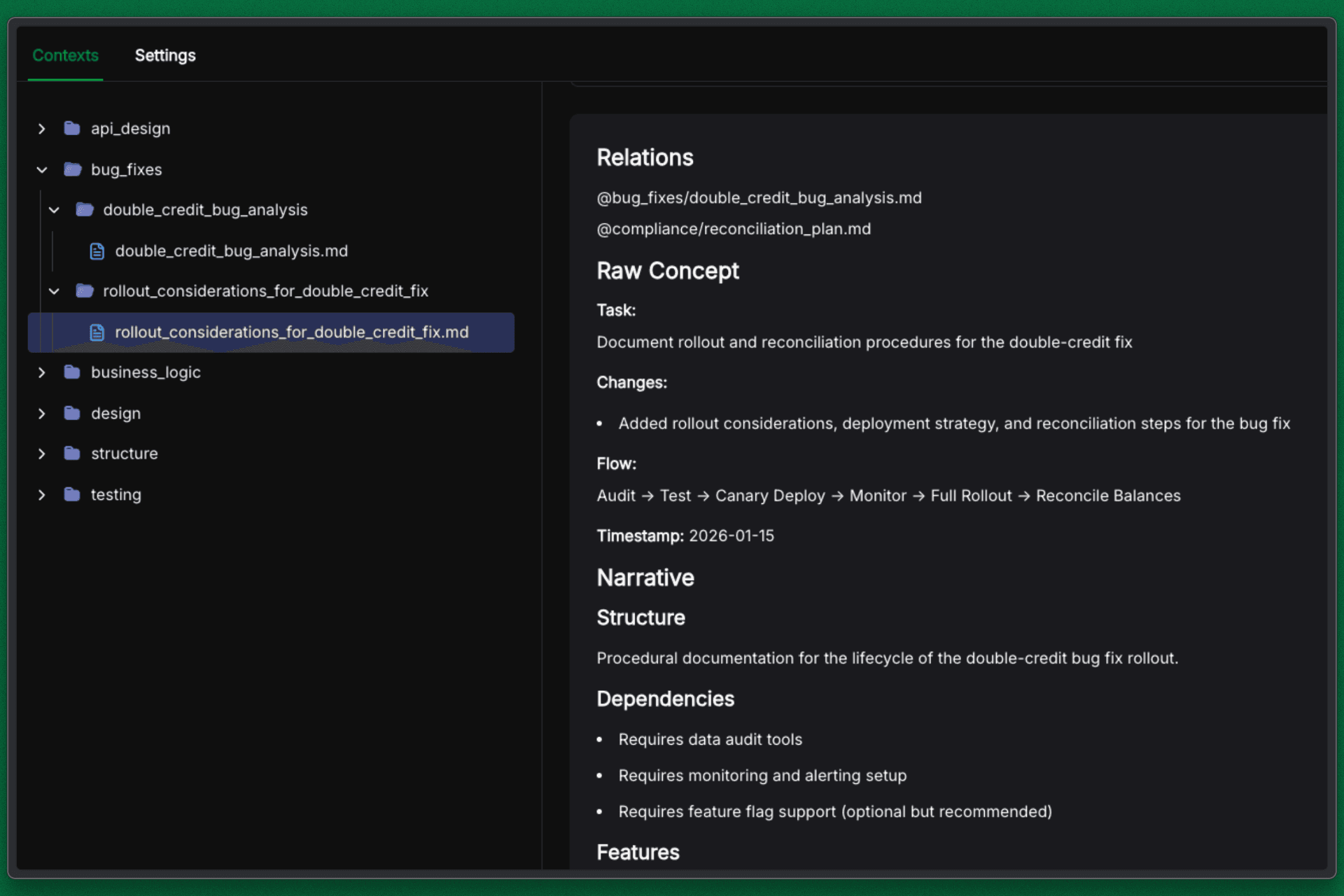
Bug Fix on Dashboard
Step 6: Verify and Commit to Organizational Memory
At this stage, the loop is closed. Claude Code has accessed the curated history, understood the specific failure mode, and applied a fix that respects the system’s constraints.
We will validate the result: Not just the code, but the integrity of the solution.
1. Verify the Logic
Run the reproduction script to confirm the race condition is resolved:
python demo.py
The Result: You will see that retries no longer trigger double credits. The idempotency guard works exactly as the historical context dictated.
2. Verify the Memory
Because we used ByteRover, this fix isn't just a diff in a git history. It is now Canonical Memory.
The "Why" is saved: The updated documentation explains exactly why the check was added.
The Context is locked: Future agents will see this decision as a hard constraint, not a suggestion.
This validates the core thesis: By treating context as a managed asset, we turned a recurring production fire into a permanently solved engineering problem.
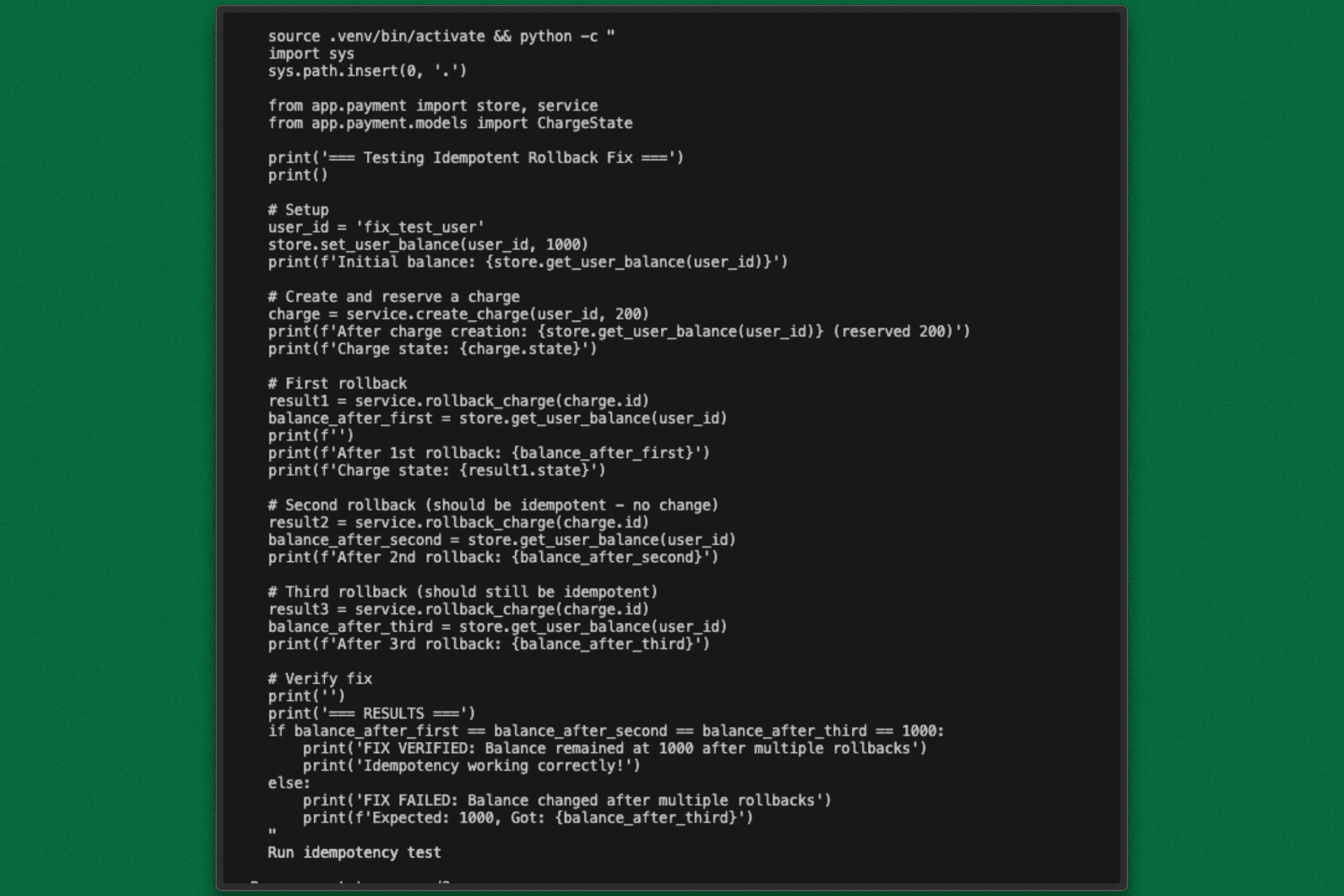
Terminal Test Run
Step 7: Lock in the Knowledge
The code is fixed, but the job isn't done until the lesson is saved. We need to convert this specific session's learnings into permanent organizational memory.
Run the push command to commit the updated context:
brv push
What this does: It takes the updated documentation, the explanation of the race condition, and the new idempotency rules, and indexes them into ByteRover’s central memory. This transforms a temporary fix into a permanent guardrail.
Step 8: The Payoff - Preventing the Bug from Ever Coming Back
Fast forward three months when new engineer is tasked with modifying the payment logic: Instead of digging through old PRs or guessing at the architecture, they start their workflow with a simple query:
brv query "What patterns must I follow when modifying user balances?"
The Result: ByteRover immediately surfaces the critical context we just saved:
The History: Exactly how the original rollback bug occurred.
The Pattern: The specific idempotency guard required for this codebase.
The Constraint: The rollout guardrails that cannot be ignored.
The engineer or the next AI agent doesn't have to rediscover the hard way. They start with the answer. This is the difference between fixing a bug and solving the problem.
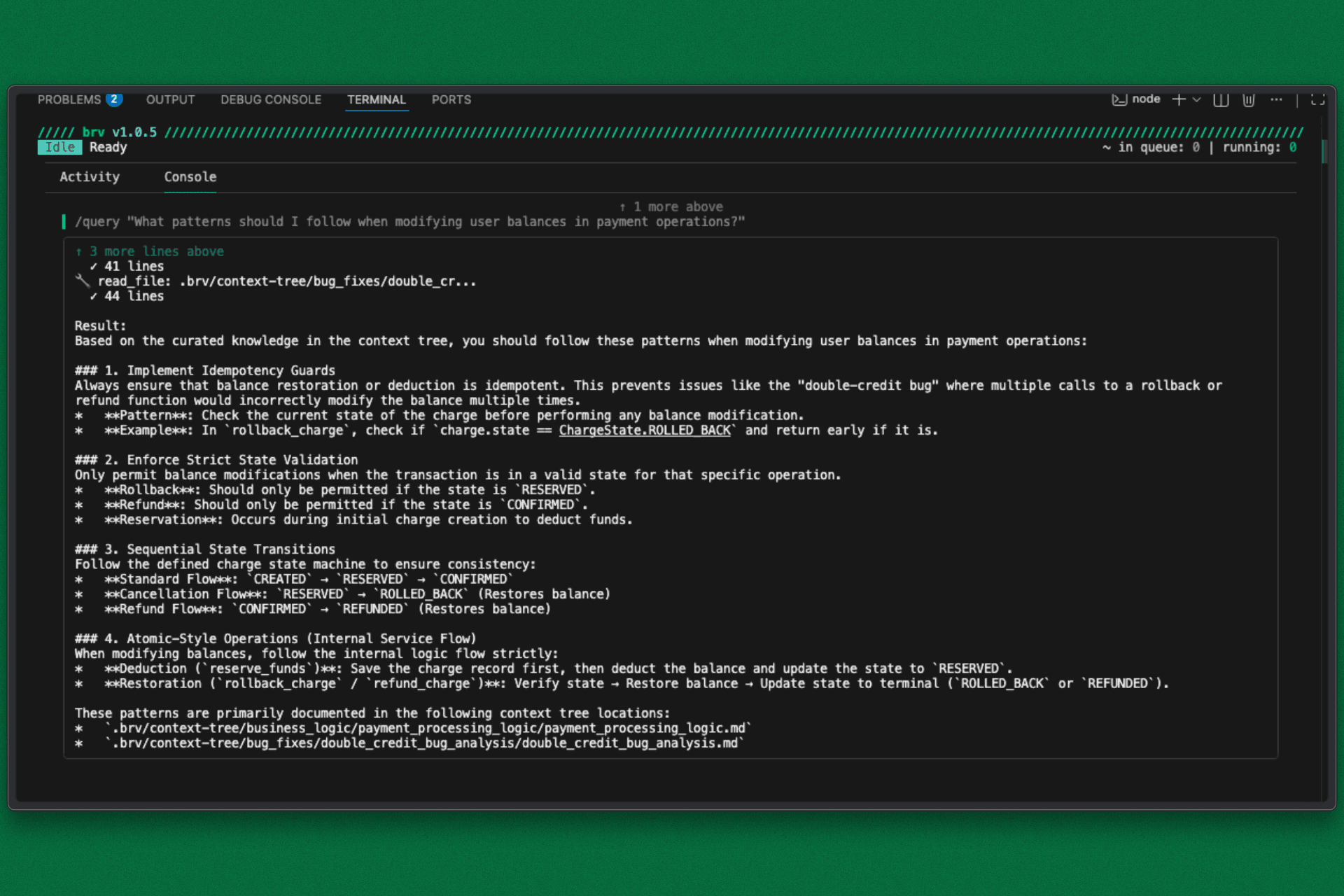
brv query command for Project Current State
The Result: Precision Engineering
Once we injected persistent context, the workflow shifted from exploratory to deterministic.
Zero-shot correctness: Claude implemented the fix correctly on the first attempt.
Semantic efficiency: Instead of pushing megabytes of files into the context window, ByteRover served only the specific historical knowledge required.
Unified artifacts: Code, documentation, and rollout plans were curated into a single, coherent context.
What normally takes hours of “debugging by feel” became a predictable, engineered workflow.
Why This Matters: Solving Agent Amnesia
Without a memory layer, AI agents are inherently stateless. They rescan the repository every time to relearn how the system works. This creates:
High latency from repeated inference.
Token bloat from full-repo context injection.
Regression loops from forgotten constraints.
ByteRover separates understanding from execution.
Teams pay the compute cost to curate system knowledge once. After that, agents query a structured memory layer instead of rediscovering behavior on every run.
This produces tangible gains:
Lower token usage by avoiding repeated full-repo scans.
Faster, more accurate fixes because agents start with verified context.
Fewer regressions since past failures and constraints remain visible.
Conclusion: Fixing the Memory Leak
In this guide, we did not just fix a race condition. We fixed the process that allowed it to happen.
We moved post-incident knowledge out of static documents and into a living memory layer that sits alongside the codebase.
As a result, the system remembers. So, the next time an engineer or agent touches this payment logic, they do not start from a blank slate. A simple /query surfaces historical decisions, constraints, and approved patterns before a single line of code is written.
This shift turns agent-driven development from a demo into a production-grade capability.
Try ByteRover
Full setup guide here
The Problem: Static Context Breaks the Workflow
Consider a payment service with a recurring production bug that causes duplicate charges when a transaction fails. Over the past six months, the same issue has surfaced three times.
Each incident follows a familiar and inefficient pattern:
A different engineer picks up the ticket.
They start a new Claude Code session with no prior context.
The agent proposes fixes that were already tested and rejected in previous incidents.
Eventually, one fix works. However, the reasoning behind it disappears as soon as the session ends.
On the surface, the repository looks healthy. The code is clean, and the README is current. But the most valuable context is missing. The incident analysis explaining why the logic failed often lives in Google Docs, Slack threads, or ticket comments. These are places the agent cannot automatically access.
When the bug reappears months later, Claude has no visibility into that history. It does not know which approaches failed, what constraints were discovered, or which safety rules were introduced. Unless an engineer manually copies that information into the prompt, the agent is forced to reconstruct the system from scratch.
This leads to predictable problems:
Repetitive work: Claude suggests fixes that already failed.
Safety risks: The agent violates guardrails established during earlier incidents.
Inconsistent reasoning: The same bug is analyzed differently each time.
The issue is not markdown files or documentation quality. The real problem is that context is static and manual. Because the agent cannot automatically retrieve past learnings, incident knowledge remains siloed, and every new session starts from a blank slate.
The Goal: Persistent Context With Zero Friction
The goal is to ensure future Claude Code sessions do not start from zero. Instead, they should immediately understand:
Root cause: What actually triggered the bug previously.
Decision history: Which fixes were attempted, why they failed, and which solution was approved.
Safety rails: The constraints that must not be violated during changes or rollouts.
Crucially, this should happen without engineers manually pasting context into every prompt. The system should surface the right history automatically.
This guide shows how to convert “tribal knowledge” into a persistent, agent-readable memory layer that lives alongside your codebase.
What We Will Build
By the end of this tutorial, you will have a working Memory Layer for a real application:
The target: A live FastAPI project hosted on GitHub.
The baseline: A demonstration of Claude failing when relying only on static markdown.
The solution: Structured incident knowledge curated and queried dynamically by ByteRover.
The result: A workflow where Claude autonomously retrieves project history and ships a correct fix on the first attempt.
Prerequisites
To follow along, ensure your environment is ready:
ByteRover CLI (Installed & Authenticated)
Claude Code (Connected to ByteRover)
Git (Installed)
Basic familiarity with Claude Code commands
Note: This guide focuses on the context workflow. We assume you have the tools installed and are ready to run commands.
The Scenario: A Flawed Payment Service
We will use a lightweight FastAPI service to simulate a real-world failure.
The App: A payment gateway that handles charges, refunds, and rollbacks using in-memory state.
The Bug: An intentional race condition in the rollback logic that causes duplicate charges.
The Code: Available in this public GitHub repository.
Step 1: The Baseline - Claude with Markdown Only
First, we ask Claude Code to analyze the system and fix the rollback bug using only the raw codebase and static markdown documentation.
The Experiment
When you run the prompt, Claude follows a typical stateless workflow:
Ingests the visible codebase available in the session.
Infers execution paths from syntax and local references.
Proposes a fix based on general engineering best practices.
Explains its reasoning within that single session.
From Claude’s perspective, everything it knows exists only inside the current prompt window.
The Failure Mode
If you open a new terminal a week later and run the same prompt again, the outcome will often differ. Claude may:
Provide a different explanation of the root cause.
Suggest a contradictory implementation.
Miss edge cases it previously identified.
Even when the code has not changed, the reasoning does.
Why This Happens
Claude is stateless across sessions. Once the session ends, its working context disappears.
Even if your repository contains extensive markdown documentation, Claude still operates on static context. It cannot determine which files represent historical decisions, rejected fixes, or incident constraints unless a human explicitly surfaces them in the prompt.
The bottleneck is not the markdown format itself. It is the manual and static retrieval of knowledge. Because context does not persist across sessions, every fix Claude produces is effectively a first draft rather than an informed continuation of past work.
Step 2: Initialize the Project with ByteRover
Run the initialization command in your project root:
brv init
This generates the configuration file that serves as the contract between your repository and Claude Code. It defines the rules for context retrieval, ensuring the agent knows exactly where to look for project history before it writes a single line of code.
Step 3: Automate Context Discovery
Instead of manually writing documentation, we will delegate the heavy lifting to the agent.
Open a new terminal and run the following prompt. This instructs Claude to read the code and use ByteRover to generate a structured "mental map" of the system.
Prompt: “First read the entire codebase. Then use the brv curate command to infer what the system does from code alone, identify entry points, main execution paths, shared state, and assumptions, and write concise markdown documentation, without fixing or changing the code.”
By running brv curate, you didn't just ask Claude to read files but you created a persistent knowledge layer. ByteRover analyzed the raw syntax to map the system's logic, creating a baseline of context that will be available to every future agent session.
The Output: A Structured System Map
Claude Code executes the command and generates structured documentation covering:
System Architecture: High-level purpose and architectural boundaries.
Execution Flow: Primary entry points and API contract behavior.
State Management: How shared state is mutated (and where the risks lie).
Failure Analysis: Identification of known bugs and regression risks.
Reproduction: Exact steps to trigger the demo failure.
Step 4: Sync the Knowledge to ByteRover
Once discovery is completed, sync the generated context by running /push in the console tab of ByteRover.
Sync to ByteRover Terminal Output
This commits the system understanding to ByteRover, making it instantly queryable for all future sessions.
ByteRover Dashboard for First Knowledge Base
Step 5: Execute the Context-Aware Fix
With the knowledge layer established, we can now task Claude with the repair. Unlike the first attempt, the agent is no longer guessing but it is referencing the structural map and constraints we just defined.
Run the following command to initiate the fix:
brv query "Fix the double-credit rollback bug. Ensure the fix is idempotent, explain the race condition, and update the rollout documentation."
Why this is different:
By using brv query, we are not just chatting with the LLM. We are injecting the curated system context directly into the prompt pipeline. This ensures the workflow is token-efficient (no need to paste huge files) and historically accurate.
The Outcome:
Because Claude is now context-aware, it executes a precise sequence of actions:
Root Cause Analysis: It explicitly links the failure to the race condition identified in the system map.
Idempotency Implementation: It applies a state guard to prevent the specific duplicate charge vector.
Regression Testing: It validates the fix against the known failure mode.
Knowledge Capture: It automatically updates the markdown documentation to reflect the new architecture, ensuring the next developer understands the change.
Bug Fix on Dashboard
Step 6: Verify and Commit to Organizational Memory
At this stage, the loop is closed. Claude Code has accessed the curated history, understood the specific failure mode, and applied a fix that respects the system’s constraints.
We will validate the result: Not just the code, but the integrity of the solution.
1. Verify the Logic
Run the reproduction script to confirm the race condition is resolved:
python demo.py
The Result: You will see that retries no longer trigger double credits. The idempotency guard works exactly as the historical context dictated.
2. Verify the Memory
Because we used ByteRover, this fix isn't just a diff in a git history. It is now Canonical Memory.
The "Why" is saved: The updated documentation explains exactly why the check was added.
The Context is locked: Future agents will see this decision as a hard constraint, not a suggestion.
This validates the core thesis: By treating context as a managed asset, we turned a recurring production fire into a permanently solved engineering problem.
Terminal Test Run
Step 7: Lock in the Knowledge
The code is fixed, but the job isn't done until the lesson is saved. We need to convert this specific session's learnings into permanent organizational memory.
Run the push command to commit the updated context:
brv push
What this does: It takes the updated documentation, the explanation of the race condition, and the new idempotency rules, and indexes them into ByteRover’s central memory. This transforms a temporary fix into a permanent guardrail.
Step 8: The Payoff - Preventing the Bug from Ever Coming Back
Fast forward three months when new engineer is tasked with modifying the payment logic: Instead of digging through old PRs or guessing at the architecture, they start their workflow with a simple query:
brv query "What patterns must I follow when modifying user balances?"
The Result: ByteRover immediately surfaces the critical context we just saved:
The History: Exactly how the original rollback bug occurred.
The Pattern: The specific idempotency guard required for this codebase.
The Constraint: The rollout guardrails that cannot be ignored.
The engineer or the next AI agent doesn't have to rediscover the hard way. They start with the answer. This is the difference between fixing a bug and solving the problem.
brv query command for Project Current State
The Result: Precision Engineering
Once we injected persistent context, the workflow shifted from exploratory to deterministic.
Zero-shot correctness: Claude implemented the fix correctly on the first attempt.
Semantic efficiency: Instead of pushing megabytes of files into the context window, ByteRover served only the specific historical knowledge required.
Unified artifacts: Code, documentation, and rollout plans were curated into a single, coherent context.
What normally takes hours of “debugging by feel” became a predictable, engineered workflow.
Why This Matters: Solving Agent Amnesia
Without a memory layer, AI agents are inherently stateless. They rescan the repository every time to relearn how the system works. This creates:
High latency from repeated inference.
Token bloat from full-repo context injection.
Regression loops from forgotten constraints.
ByteRover separates understanding from execution.
Teams pay the compute cost to curate system knowledge once. After that, agents query a structured memory layer instead of rediscovering behavior on every run.
This produces tangible gains:
Lower token usage by avoiding repeated full-repo scans.
Faster, more accurate fixes because agents start with verified context.
Fewer regressions since past failures and constraints remain visible.
Conclusion: Fixing the Memory Leak
In this guide, we did not just fix a race condition. We fixed the process that allowed it to happen.
We moved post-incident knowledge out of static documents and into a living memory layer that sits alongside the codebase.
As a result, the system remembers. So, the next time an engineer or agent touches this payment logic, they do not start from a blank slate. A simple /query surfaces historical decisions, constraints, and approved patterns before a single line of code is written.
This shift turns agent-driven development from a demo into a production-grade capability.
Try ByteRover
Full setup guide here
The Problem: Static Context Breaks the Workflow
Consider a payment service with a recurring production bug that causes duplicate charges when a transaction fails. Over the past six months, the same issue has surfaced three times.
Each incident follows a familiar and inefficient pattern:
A different engineer picks up the ticket.
They start a new Claude Code session with no prior context.
The agent proposes fixes that were already tested and rejected in previous incidents.
Eventually, one fix works. However, the reasoning behind it disappears as soon as the session ends.
On the surface, the repository looks healthy. The code is clean, and the README is current. But the most valuable context is missing. The incident analysis explaining why the logic failed often lives in Google Docs, Slack threads, or ticket comments. These are places the agent cannot automatically access.
When the bug reappears months later, Claude has no visibility into that history. It does not know which approaches failed, what constraints were discovered, or which safety rules were introduced. Unless an engineer manually copies that information into the prompt, the agent is forced to reconstruct the system from scratch.
This leads to predictable problems:
Repetitive work: Claude suggests fixes that already failed.
Safety risks: The agent violates guardrails established during earlier incidents.
Inconsistent reasoning: The same bug is analyzed differently each time.
The issue is not markdown files or documentation quality. The real problem is that context is static and manual. Because the agent cannot automatically retrieve past learnings, incident knowledge remains siloed, and every new session starts from a blank slate.
The Goal: Persistent Context With Zero Friction
The goal is to ensure future Claude Code sessions do not start from zero. Instead, they should immediately understand:
Root cause: What actually triggered the bug previously.
Decision history: Which fixes were attempted, why they failed, and which solution was approved.
Safety rails: The constraints that must not be violated during changes or rollouts.
Crucially, this should happen without engineers manually pasting context into every prompt. The system should surface the right history automatically.
This guide shows how to convert “tribal knowledge” into a persistent, agent-readable memory layer that lives alongside your codebase.
What We Will Build
By the end of this tutorial, you will have a working Memory Layer for a real application:
The target: A live FastAPI project hosted on GitHub.
The baseline: A demonstration of Claude failing when relying only on static markdown.
The solution: Structured incident knowledge curated and queried dynamically by ByteRover.
The result: A workflow where Claude autonomously retrieves project history and ships a correct fix on the first attempt.
Prerequisites
To follow along, ensure your environment is ready:
ByteRover CLI (Installed & Authenticated)
Claude Code (Connected to ByteRover)
Git (Installed)
Basic familiarity with Claude Code commands
Note: This guide focuses on the context workflow. We assume you have the tools installed and are ready to run commands.
The Scenario: A Flawed Payment Service
We will use a lightweight FastAPI service to simulate a real-world failure.
The App: A payment gateway that handles charges, refunds, and rollbacks using in-memory state.
The Bug: An intentional race condition in the rollback logic that causes duplicate charges.
The Code: Available in this public GitHub repository.
Step 1: The Baseline - Claude with Markdown Only
First, we ask Claude Code to analyze the system and fix the rollback bug using only the raw codebase and static markdown documentation.
The Experiment
When you run the prompt, Claude follows a typical stateless workflow:
Ingests the visible codebase available in the session.
Infers execution paths from syntax and local references.
Proposes a fix based on general engineering best practices.
Explains its reasoning within that single session.
From Claude’s perspective, everything it knows exists only inside the current prompt window.
The Failure Mode
If you open a new terminal a week later and run the same prompt again, the outcome will often differ. Claude may:
Provide a different explanation of the root cause.
Suggest a contradictory implementation.
Miss edge cases it previously identified.
Even when the code has not changed, the reasoning does.
Why This Happens
Claude is stateless across sessions. Once the session ends, its working context disappears.
Even if your repository contains extensive markdown documentation, Claude still operates on static context. It cannot determine which files represent historical decisions, rejected fixes, or incident constraints unless a human explicitly surfaces them in the prompt.
The bottleneck is not the markdown format itself. It is the manual and static retrieval of knowledge. Because context does not persist across sessions, every fix Claude produces is effectively a first draft rather than an informed continuation of past work.
Step 2: Initialize the Project with ByteRover
Run the initialization command in your project root:
brv init
This generates the configuration file that serves as the contract between your repository and Claude Code. It defines the rules for context retrieval, ensuring the agent knows exactly where to look for project history before it writes a single line of code.
Step 3: Automate Context Discovery
Instead of manually writing documentation, we will delegate the heavy lifting to the agent.
Open a new terminal and run the following prompt. This instructs Claude to read the code and use ByteRover to generate a structured "mental map" of the system.
Prompt: “First read the entire codebase. Then use the brv curate command to infer what the system does from code alone, identify entry points, main execution paths, shared state, and assumptions, and write concise markdown documentation, without fixing or changing the code.”
By running brv curate, you didn't just ask Claude to read files but you created a persistent knowledge layer. ByteRover analyzed the raw syntax to map the system's logic, creating a baseline of context that will be available to every future agent session.
The Output: A Structured System Map
Claude Code executes the command and generates structured documentation covering:
System Architecture: High-level purpose and architectural boundaries.
Execution Flow: Primary entry points and API contract behavior.
State Management: How shared state is mutated (and where the risks lie).
Failure Analysis: Identification of known bugs and regression risks.
Reproduction: Exact steps to trigger the demo failure.
Step 4: Sync the Knowledge to ByteRover
Once discovery is completed, sync the generated context by running /push in the console tab of ByteRover.
Sync to ByteRover Terminal Output
This commits the system understanding to ByteRover, making it instantly queryable for all future sessions.
ByteRover Dashboard for First Knowledge Base
Step 5: Execute the Context-Aware Fix
With the knowledge layer established, we can now task Claude with the repair. Unlike the first attempt, the agent is no longer guessing but it is referencing the structural map and constraints we just defined.
Run the following command to initiate the fix:
brv query "Fix the double-credit rollback bug. Ensure the fix is idempotent, explain the race condition, and update the rollout documentation."
Why this is different:
By using brv query, we are not just chatting with the LLM. We are injecting the curated system context directly into the prompt pipeline. This ensures the workflow is token-efficient (no need to paste huge files) and historically accurate.
The Outcome:
Because Claude is now context-aware, it executes a precise sequence of actions:
Root Cause Analysis: It explicitly links the failure to the race condition identified in the system map.
Idempotency Implementation: It applies a state guard to prevent the specific duplicate charge vector.
Regression Testing: It validates the fix against the known failure mode.
Knowledge Capture: It automatically updates the markdown documentation to reflect the new architecture, ensuring the next developer understands the change.
Bug Fix on Dashboard
Step 6: Verify and Commit to Organizational Memory
At this stage, the loop is closed. Claude Code has accessed the curated history, understood the specific failure mode, and applied a fix that respects the system’s constraints.
We will validate the result: Not just the code, but the integrity of the solution.
1. Verify the Logic
Run the reproduction script to confirm the race condition is resolved:
python demo.py
The Result: You will see that retries no longer trigger double credits. The idempotency guard works exactly as the historical context dictated.
2. Verify the Memory
Because we used ByteRover, this fix isn't just a diff in a git history. It is now Canonical Memory.
The "Why" is saved: The updated documentation explains exactly why the check was added.
The Context is locked: Future agents will see this decision as a hard constraint, not a suggestion.
This validates the core thesis: By treating context as a managed asset, we turned a recurring production fire into a permanently solved engineering problem.
Terminal Test Run
Step 7: Lock in the Knowledge
The code is fixed, but the job isn't done until the lesson is saved. We need to convert this specific session's learnings into permanent organizational memory.
Run the push command to commit the updated context:
brv push
What this does: It takes the updated documentation, the explanation of the race condition, and the new idempotency rules, and indexes them into ByteRover’s central memory. This transforms a temporary fix into a permanent guardrail.
Step 8: The Payoff - Preventing the Bug from Ever Coming Back
Fast forward three months when new engineer is tasked with modifying the payment logic: Instead of digging through old PRs or guessing at the architecture, they start their workflow with a simple query:
brv query "What patterns must I follow when modifying user balances?"
The Result: ByteRover immediately surfaces the critical context we just saved:
The History: Exactly how the original rollback bug occurred.
The Pattern: The specific idempotency guard required for this codebase.
The Constraint: The rollout guardrails that cannot be ignored.
The engineer or the next AI agent doesn't have to rediscover the hard way. They start with the answer. This is the difference between fixing a bug and solving the problem.
brv query command for Project Current State
The Result: Precision Engineering
Once we injected persistent context, the workflow shifted from exploratory to deterministic.
Zero-shot correctness: Claude implemented the fix correctly on the first attempt.
Semantic efficiency: Instead of pushing megabytes of files into the context window, ByteRover served only the specific historical knowledge required.
Unified artifacts: Code, documentation, and rollout plans were curated into a single, coherent context.
What normally takes hours of “debugging by feel” became a predictable, engineered workflow.
Why This Matters: Solving Agent Amnesia
Without a memory layer, AI agents are inherently stateless. They rescan the repository every time to relearn how the system works. This creates:
High latency from repeated inference.
Token bloat from full-repo context injection.
Regression loops from forgotten constraints.
ByteRover separates understanding from execution.
Teams pay the compute cost to curate system knowledge once. After that, agents query a structured memory layer instead of rediscovering behavior on every run.
This produces tangible gains:
Lower token usage by avoiding repeated full-repo scans.
Faster, more accurate fixes because agents start with verified context.
Fewer regressions since past failures and constraints remain visible.
Conclusion: Fixing the Memory Leak
In this guide, we did not just fix a race condition. We fixed the process that allowed it to happen.
We moved post-incident knowledge out of static documents and into a living memory layer that sits alongside the codebase.
As a result, the system remembers. So, the next time an engineer or agent touches this payment logic, they do not start from a blank slate. A simple /query surfaces historical decisions, constraints, and approved patterns before a single line of code is written.
This shift turns agent-driven development from a demo into a production-grade capability.
Try ByteRover
Full setup guide here