
1. The Context Gap Problem
As development teams increasingly integrate AI agents into their workflows, a critical bottleneck has emerged: Context.
For an AI coding agent to truly act as a developer being able to refactor legacy modules, debug complex race conditions, or implement new features, it requires a deep, structural understanding of the codebase. The industry standard approach, Vector RAG (Retrieval-Augmented Generation), treats code primarily as text. It chunks files, creates embeddings, and performs similarity searches.
However, code is not a flat "bag of words" but rather a complex, hierarchical tree defined by strict architectural boundaries and dependency chains.
At ByteRover, we hypothesized that the limitations of similarity-based retrieval were blocking agent performance. To test this, we conducted an experiment on a production codebase of 1,300 files. We compared traditional Vector RAG against Context Tree, a memory architecture available in ByteRover 3.0. The architecture is organized in a tree where domains are dynamically derived from what the codebase has, such as technical stacks, functional domains, coding conventions or architectural decisions. The results were definitive: By shifting from similarity-based retrieval to a structured, domain-structured architecture, we achieved 99.2% token reduction and 2.2× better precision.
This article will explain why Vector RAG struggles with code and how domain-structured memory solves the context gap.
2. Redefining Codebase Memory with Domain-Structured Memory and Intent-Aware Retrieval
Before analyzing the data, it is essential to distinguish between the two core components of an AI coding agent’s memory system: the Storage Architecture and the Retrieval Process.
The Storage Architecture: Vector Database vs. Context Tree
Vector databases store code as isolated snippets floating in a high-dimensional vector space and relationships are inferred solely through semantic similarity.
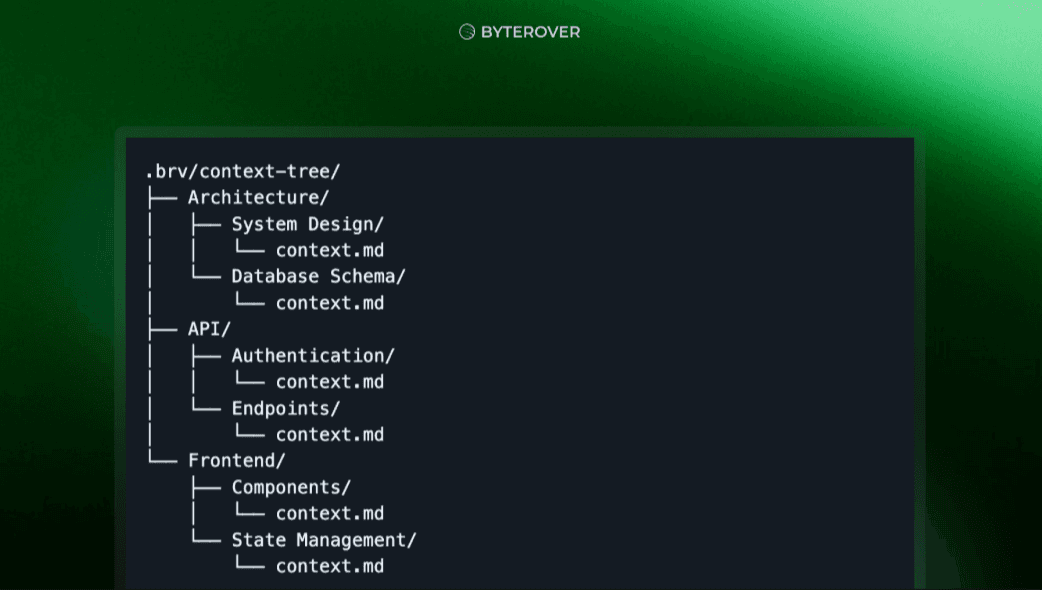
In contrast, ByteRover utilizes a Context Tree. This is a hierarchical memory architecture that organizes codebase into:
Domains: High-level categories (e.g., Architecture, API, Frontend).
Topics: Specific subjects within domains (e.g., Authentication, Components).
Context Files: Markdown files containing your actual knowledge.
Whenever you store new memories, ByteRover agent automatically organizes them into precise knowledge locations within a persistent, filesystem-based structure.
The Retrieval Process: Cosine Similarity vs. Agentic Search
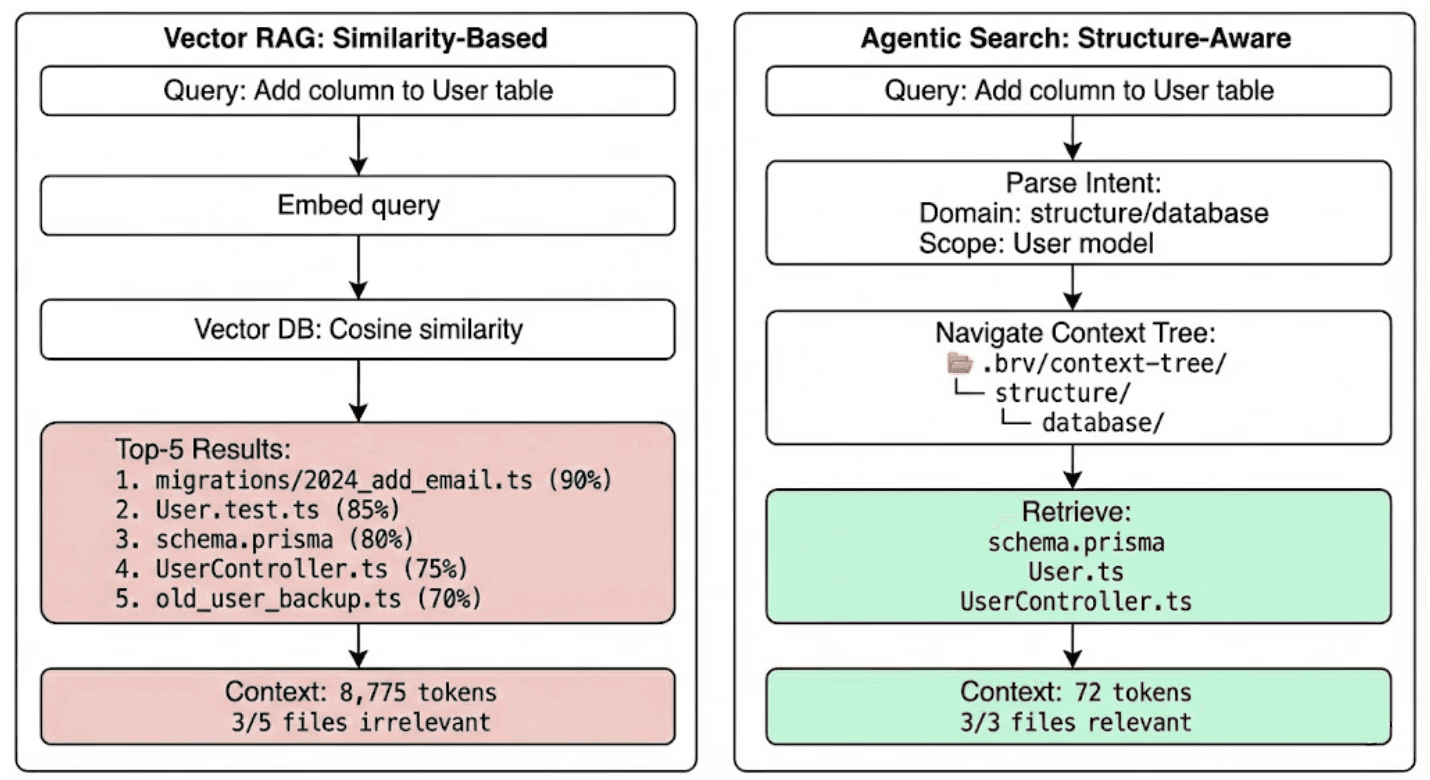
Standard RAG relies on Cosine Similarity that find chunks mathematically similar to these keywords. When a query comes in, RAG will fetch top 5 most similar chunks. For example, if developers ask to update the auth controller to use refresh tokens, vector RAG will retrieve:
AuthController.ts✅ (the actual file you need)AuthController.test.ts❌ (test file, not implementation)Old_Auth_Backup.ts❌ (deprecated code from last year)Auth_v2_migration.ts❌ (historical migration script)UserController.ts❌ (mentions "auth" in a comment, completely unrelated)
All five files score above 70% similarity because they share keywords: "auth", "controller", "token", "user" but only one file is actually relevant. This implies agent has 80% noise in its context window, causing hallucinations, wasted tokens, and confused reasoning.
ByteRover uses new technique: Agentic Search. This is a domain-structured retrieval process that first analyzes the user's intent and then navigates directly to the relevant part of your codebase, enabling:
More accurate, task-specific retrieval.
Less noise and irrelevant piece of context.
How Agentic Search works:
Parse the query to understand user intent
Navigate the context tree hierarchy
Follow explicit relations between topics
Return an answer and file paths, not full file contents
3. The Experiment: Comparing Retrieval Strategies
To measure the impact of this architectural shift, we ran 30 distinct engineering queries against gemini-cli, a real-world production TypeScript codebase containing approximately 1,300 files.
We compared two systems:
Vector RAG Baseline: OpenAI embeddings (
text-embedding-3-small) stored in Qdrant, retrieving the top-5 chunks via cosine similarity.Agentic Search: ByteRover’s Context Tree system with pre-curated knowledge.
The Results
The performance gap between similarity-based retrieval and domain-structured retrieval was significant.
Metric | Vector RAG | Agentic Search | Difference |
|---|---|---|---|
Token Usage | 8,775 | 72 | 99.2% reduction |
Precision | 0.053 | 0.117 | 2.2× better |
Recall | 0.108 | 0.097 | 10% lower |
IoU (Overall Accuracy) | 0.036 | 0.073 | 2× better |
Key Takeaway: 130x Token Efficiency and 2.2x Retrieval Precision
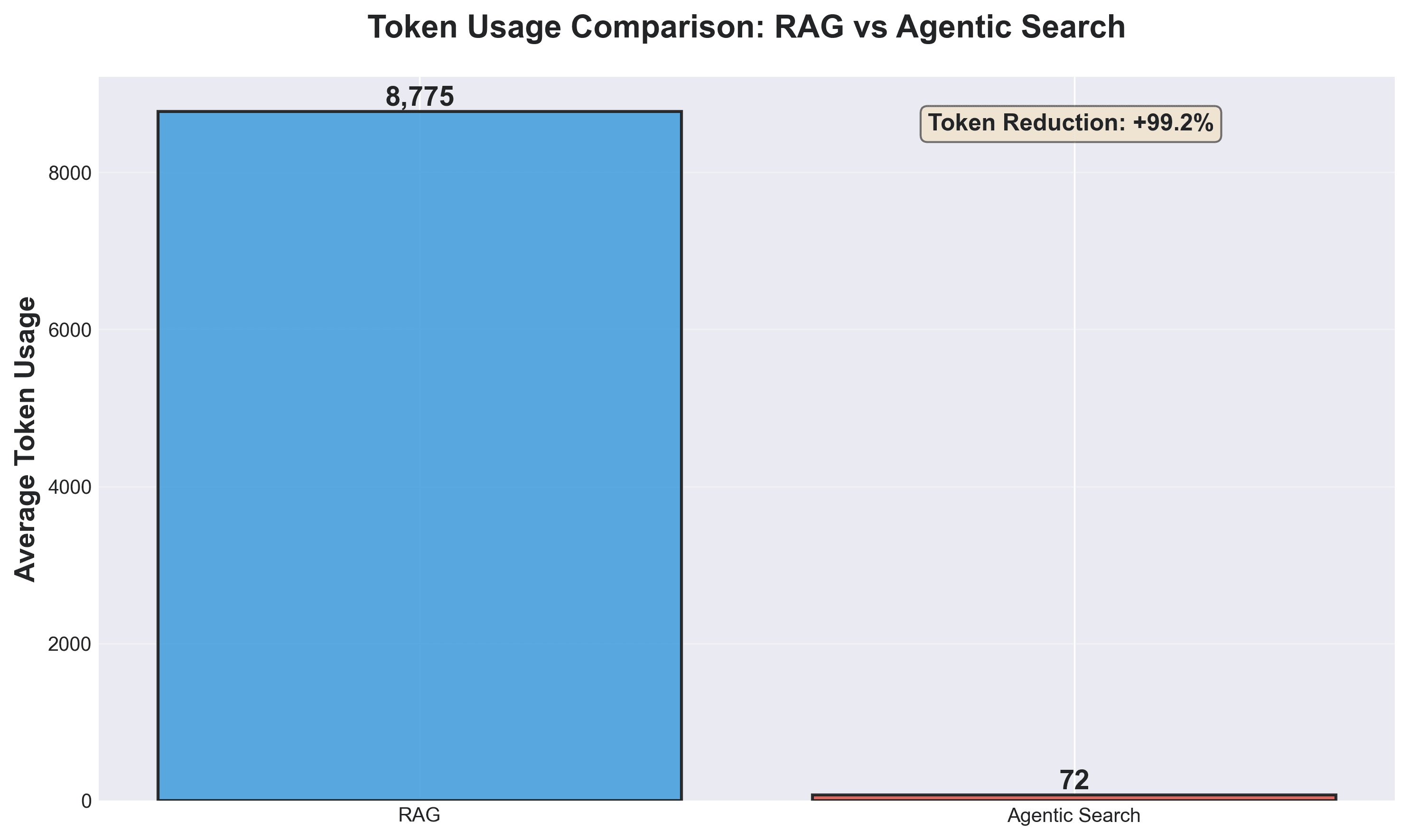
The most striking metric is the 130× difference in token efficiency. Vector RAG typically dumps full file contents into the context window with 8,775 tokens per query on average, meaning a 500-line test file weighs the same as a a 50-line interface definition.
Agentic Search, conversely, returns targeted answers with specific file paths, consuming only 72 tokens per query. For example:
"OAuth2 is implemented in packages/core/src/code_assist/oauth2.ts. See also the MCP OAuth provider in packages/core/src/mcp/oauth-provider.ts."
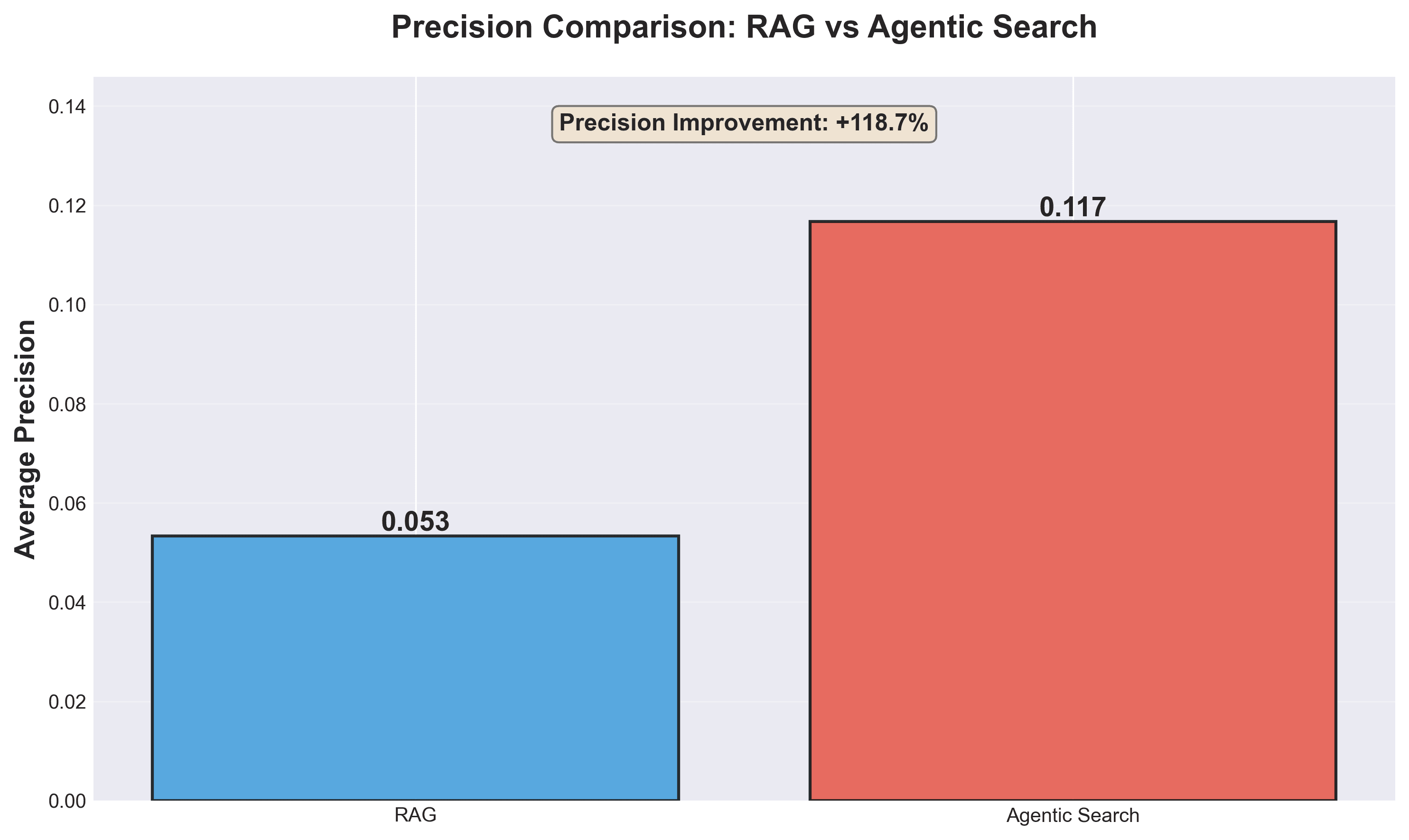
Agentic Search achieves 2.2× higher precision (0.117 vs 0.053).
The reason is because Vector RAG can't tell current code from historical artifacts. It sees AuthController.ts and Auth_v2_migration.ts as equally relevant because they share keywords. In contrast, the Context Tree maintains an accurate snapshot of the system's current status. Instead of just storing code, it captures the active implementation alongside key decisions in natural language that explain why the code arrived at this state. This ensures the agent builds upon the live architecture rather than hallucinating based on dead code or deprecated migration scripts.
4. Why Vector RAG Breaks: The "Similarity" Trap
Through our research, we identified three primary failure modes where similarity-based retrieval actively degrades agent performance.
Failure Mode #1: Pattern Matching vs. Architectural Relevance
Codebases are full of repeated patterns: error handling, logging, and authentication checks. If an engineer asks to update the auth controller a Vector RAG system will retrieve any file containing "auth," "user," or "controller." This often includes HTTP middleware, database utilities, and unrelated unit tests. They all score high on similarity because they share keywords, but they lack architectural relevance.
Failure Mode #2: The Museum Problem
Embeddings struggle to distinguish between the current state of the code and historical artifacts. In a messy production environment, AuthController.ts (active) and Old_Auth_Backup.ts (deprecated) often contain identical class names and function signatures. To an embedding model, they look nearly identical. This leads agents to import from dead code or hallucinate based on deprecated logic.
Failure Mode #3: Context Dilution
Most Vector RAG systems rely on a fixed top-k retrieval (e.g., top 5). This approach lacks nuance:
• Simple Query: "Where is OAuth2 defined?" (Needs 1 file) → RAG returns 5 files (80% noise).
• Complex Query: "Find all auth-related files." (Needs 15 files) → RAG returns 5 files (Significant context missing).
5. The Solution: Context Tree and Agentic Search
ByteRover 3.0 solves these issues by structuring memory the way engineers structure mental models: hierarchically.
Structured Knowledge Storage
Instead of a flat index, the Context Tree organizes the codebase into a navigable file system structure within .brv/context-tree/ .
.brv/context-tree/ ├── structure/ │ ├── authentication/ │ │ ├── oauth2/ │ │ │ └── oauth2-impl.md → Implementation: oauth2.ts, oauth-provider.ts │ │ └── api-keys/ │ │ └── storage-strategy.md → Implementation: apiKeyCredentialStorage.ts │ └── mcp/ │ └── integration.md → Related: @structure/authentication/oauth2
Intent-Driven Retrieval
When a query enters the system, Agentic Search does not look for keywords. It parses intent:
Analyze Request: "Add a new auth method."
Map to Domain: Identify the
structure/authenticationdomain.Traverse Relationships: Follow explicit links (e.g.,
@structure/authentication/oauth2) to pull in necessary dependencies like the MCP provider.
This results in an accurate snapshot of what is current, alongside the reasoning for why the code exists, without the noise of deprecated backups or unrelated test files.
6. Conclusion
The transition from Vector RAG to Context Trees represents a fundamental shift in how we engineer AI coding agents. To be effective partners, agents must respect that code is a sophisticated tree with architectural boundaries, not merely a collection of text chunks.
By adopting a domain-structured memory architecture, engineering teams can significantly reduce token costs, eliminate hallucinations caused by "dead code," and improve the reasoning capabilities of their coding agents.
Try It Yourself
Learn more about Context Tree and Agentic Search: ByteRover
All code, data, and visualizations are open sourced in this repo
1. The Context Gap Problem
As development teams increasingly integrate AI agents into their workflows, a critical bottleneck has emerged: Context.
For an AI coding agent to truly act as a developer being able to refactor legacy modules, debug complex race conditions, or implement new features, it requires a deep, structural understanding of the codebase. The industry standard approach, Vector RAG (Retrieval-Augmented Generation), treats code primarily as text. It chunks files, creates embeddings, and performs similarity searches.
However, code is not a flat "bag of words" but rather a complex, hierarchical tree defined by strict architectural boundaries and dependency chains.
At ByteRover, we hypothesized that the limitations of similarity-based retrieval were blocking agent performance. To test this, we conducted an experiment on a production codebase of 1,300 files. We compared traditional Vector RAG against Context Tree, a memory architecture available in ByteRover 3.0. The architecture is organized in a tree where domains are dynamically derived from what the codebase has, such as technical stacks, functional domains, coding conventions or architectural decisions. The results were definitive: By shifting from similarity-based retrieval to a structured, domain-structured architecture, we achieved 99.2% token reduction and 2.2× better precision.
This article will explain why Vector RAG struggles with code and how domain-structured memory solves the context gap.
2. Redefining Codebase Memory with Domain-Structured Memory and Intent-Aware Retrieval
Before analyzing the data, it is essential to distinguish between the two core components of an AI coding agent’s memory system: the Storage Architecture and the Retrieval Process.
The Storage Architecture: Vector Database vs. Context Tree
Vector databases store code as isolated snippets floating in a high-dimensional vector space and relationships are inferred solely through semantic similarity.
In contrast, ByteRover utilizes a Context Tree. This is a hierarchical memory architecture that organizes codebase into:
Domains: High-level categories (e.g., Architecture, API, Frontend).
Topics: Specific subjects within domains (e.g., Authentication, Components).
Context Files: Markdown files containing your actual knowledge.
Whenever you store new memories, ByteRover agent automatically organizes them into precise knowledge locations within a persistent, filesystem-based structure.
The Retrieval Process: Cosine Similarity vs. Agentic Search
Standard RAG relies on Cosine Similarity that find chunks mathematically similar to these keywords. When a query comes in, RAG will fetch top 5 most similar chunks. For example, if developers ask to update the auth controller to use refresh tokens, vector RAG will retrieve:
AuthController.ts✅ (the actual file you need)AuthController.test.ts❌ (test file, not implementation)Old_Auth_Backup.ts❌ (deprecated code from last year)Auth_v2_migration.ts❌ (historical migration script)UserController.ts❌ (mentions "auth" in a comment, completely unrelated)
All five files score above 70% similarity because they share keywords: "auth", "controller", "token", "user" but only one file is actually relevant. This implies agent has 80% noise in its context window, causing hallucinations, wasted tokens, and confused reasoning.
ByteRover uses new technique: Agentic Search. This is a domain-structured retrieval process that first analyzes the user's intent and then navigates directly to the relevant part of your codebase, enabling:
More accurate, task-specific retrieval.
Less noise and irrelevant piece of context.
How Agentic Search works:
Parse the query to understand user intent
Navigate the context tree hierarchy
Follow explicit relations between topics
Return an answer and file paths, not full file contents
3. The Experiment: Comparing Retrieval Strategies
To measure the impact of this architectural shift, we ran 30 distinct engineering queries against gemini-cli, a real-world production TypeScript codebase containing approximately 1,300 files.
We compared two systems:
Vector RAG Baseline: OpenAI embeddings (
text-embedding-3-small) stored in Qdrant, retrieving the top-5 chunks via cosine similarity.Agentic Search: ByteRover’s Context Tree system with pre-curated knowledge.
The Results
The performance gap between similarity-based retrieval and domain-structured retrieval was significant.
Metric | Vector RAG | Agentic Search | Difference |
|---|---|---|---|
Token Usage | 8,775 | 72 | 99.2% reduction |
Precision | 0.053 | 0.117 | 2.2× better |
Recall | 0.108 | 0.097 | 10% lower |
IoU (Overall Accuracy) | 0.036 | 0.073 | 2× better |
Key Takeaway: 130x Token Efficiency and 2.2x Retrieval Precision
The most striking metric is the 130× difference in token efficiency. Vector RAG typically dumps full file contents into the context window with 8,775 tokens per query on average, meaning a 500-line test file weighs the same as a a 50-line interface definition.
Agentic Search, conversely, returns targeted answers with specific file paths, consuming only 72 tokens per query. For example:
"OAuth2 is implemented in packages/core/src/code_assist/oauth2.ts. See also the MCP OAuth provider in packages/core/src/mcp/oauth-provider.ts."
Agentic Search achieves 2.2× higher precision (0.117 vs 0.053).
The reason is because Vector RAG can't tell current code from historical artifacts. It sees AuthController.ts and Auth_v2_migration.ts as equally relevant because they share keywords. In contrast, the Context Tree maintains an accurate snapshot of the system's current status. Instead of just storing code, it captures the active implementation alongside key decisions in natural language that explain why the code arrived at this state. This ensures the agent builds upon the live architecture rather than hallucinating based on dead code or deprecated migration scripts.
4. Why Vector RAG Breaks: The "Similarity" Trap
Through our research, we identified three primary failure modes where similarity-based retrieval actively degrades agent performance.
Failure Mode #1: Pattern Matching vs. Architectural Relevance
Codebases are full of repeated patterns: error handling, logging, and authentication checks. If an engineer asks to update the auth controller a Vector RAG system will retrieve any file containing "auth," "user," or "controller." This often includes HTTP middleware, database utilities, and unrelated unit tests. They all score high on similarity because they share keywords, but they lack architectural relevance.
Failure Mode #2: The Museum Problem
Embeddings struggle to distinguish between the current state of the code and historical artifacts. In a messy production environment, AuthController.ts (active) and Old_Auth_Backup.ts (deprecated) often contain identical class names and function signatures. To an embedding model, they look nearly identical. This leads agents to import from dead code or hallucinate based on deprecated logic.
Failure Mode #3: Context Dilution
Most Vector RAG systems rely on a fixed top-k retrieval (e.g., top 5). This approach lacks nuance:
• Simple Query: "Where is OAuth2 defined?" (Needs 1 file) → RAG returns 5 files (80% noise).
• Complex Query: "Find all auth-related files." (Needs 15 files) → RAG returns 5 files (Significant context missing).
5. The Solution: Context Tree and Agentic Search
ByteRover 3.0 solves these issues by structuring memory the way engineers structure mental models: hierarchically.
Structured Knowledge Storage
Instead of a flat index, the Context Tree organizes the codebase into a navigable file system structure within .brv/context-tree/ .
.brv/context-tree/ ├── structure/ │ ├── authentication/ │ │ ├── oauth2/ │ │ │ └── oauth2-impl.md → Implementation: oauth2.ts, oauth-provider.ts │ │ └── api-keys/ │ │ └── storage-strategy.md → Implementation: apiKeyCredentialStorage.ts │ └── mcp/ │ └── integration.md → Related: @structure/authentication/oauth2
Intent-Driven Retrieval
When a query enters the system, Agentic Search does not look for keywords. It parses intent:
Analyze Request: "Add a new auth method."
Map to Domain: Identify the
structure/authenticationdomain.Traverse Relationships: Follow explicit links (e.g.,
@structure/authentication/oauth2) to pull in necessary dependencies like the MCP provider.
This results in an accurate snapshot of what is current, alongside the reasoning for why the code exists, without the noise of deprecated backups or unrelated test files.
6. Conclusion
The transition from Vector RAG to Context Trees represents a fundamental shift in how we engineer AI coding agents. To be effective partners, agents must respect that code is a sophisticated tree with architectural boundaries, not merely a collection of text chunks.
By adopting a domain-structured memory architecture, engineering teams can significantly reduce token costs, eliminate hallucinations caused by "dead code," and improve the reasoning capabilities of their coding agents.
Try It Yourself
Learn more about Context Tree and Agentic Search: ByteRover
All code, data, and visualizations are open sourced in this repo
1. The Context Gap Problem
As development teams increasingly integrate AI agents into their workflows, a critical bottleneck has emerged: Context.
For an AI coding agent to truly act as a developer being able to refactor legacy modules, debug complex race conditions, or implement new features, it requires a deep, structural understanding of the codebase. The industry standard approach, Vector RAG (Retrieval-Augmented Generation), treats code primarily as text. It chunks files, creates embeddings, and performs similarity searches.
However, code is not a flat "bag of words" but rather a complex, hierarchical tree defined by strict architectural boundaries and dependency chains.
At ByteRover, we hypothesized that the limitations of similarity-based retrieval were blocking agent performance. To test this, we conducted an experiment on a production codebase of 1,300 files. We compared traditional Vector RAG against Context Tree, a memory architecture available in ByteRover 3.0. The architecture is organized in a tree where domains are dynamically derived from what the codebase has, such as technical stacks, functional domains, coding conventions or architectural decisions. The results were definitive: By shifting from similarity-based retrieval to a structured, domain-structured architecture, we achieved 99.2% token reduction and 2.2× better precision.
This article will explain why Vector RAG struggles with code and how domain-structured memory solves the context gap.
2. Redefining Codebase Memory with Domain-Structured Memory and Intent-Aware Retrieval
Before analyzing the data, it is essential to distinguish between the two core components of an AI coding agent’s memory system: the Storage Architecture and the Retrieval Process.
The Storage Architecture: Vector Database vs. Context Tree
Vector databases store code as isolated snippets floating in a high-dimensional vector space and relationships are inferred solely through semantic similarity.
In contrast, ByteRover utilizes a Context Tree. This is a hierarchical memory architecture that organizes codebase into:
Domains: High-level categories (e.g., Architecture, API, Frontend).
Topics: Specific subjects within domains (e.g., Authentication, Components).
Context Files: Markdown files containing your actual knowledge.
Whenever you store new memories, ByteRover agent automatically organizes them into precise knowledge locations within a persistent, filesystem-based structure.
The Retrieval Process: Cosine Similarity vs. Agentic Search
Standard RAG relies on Cosine Similarity that find chunks mathematically similar to these keywords. When a query comes in, RAG will fetch top 5 most similar chunks. For example, if developers ask to update the auth controller to use refresh tokens, vector RAG will retrieve:
AuthController.ts✅ (the actual file you need)AuthController.test.ts❌ (test file, not implementation)Old_Auth_Backup.ts❌ (deprecated code from last year)Auth_v2_migration.ts❌ (historical migration script)UserController.ts❌ (mentions "auth" in a comment, completely unrelated)
All five files score above 70% similarity because they share keywords: "auth", "controller", "token", "user" but only one file is actually relevant. This implies agent has 80% noise in its context window, causing hallucinations, wasted tokens, and confused reasoning.
ByteRover uses new technique: Agentic Search. This is a domain-structured retrieval process that first analyzes the user's intent and then navigates directly to the relevant part of your codebase, enabling:
More accurate, task-specific retrieval.
Less noise and irrelevant piece of context.
How Agentic Search works:
Parse the query to understand user intent
Navigate the context tree hierarchy
Follow explicit relations between topics
Return an answer and file paths, not full file contents
3. The Experiment: Comparing Retrieval Strategies
To measure the impact of this architectural shift, we ran 30 distinct engineering queries against gemini-cli, a real-world production TypeScript codebase containing approximately 1,300 files.
We compared two systems:
Vector RAG Baseline: OpenAI embeddings (
text-embedding-3-small) stored in Qdrant, retrieving the top-5 chunks via cosine similarity.Agentic Search: ByteRover’s Context Tree system with pre-curated knowledge.
The Results
The performance gap between similarity-based retrieval and domain-structured retrieval was significant.
Metric | Vector RAG | Agentic Search | Difference |
|---|---|---|---|
Token Usage | 8,775 | 72 | 99.2% reduction |
Precision | 0.053 | 0.117 | 2.2× better |
Recall | 0.108 | 0.097 | 10% lower |
IoU (Overall Accuracy) | 0.036 | 0.073 | 2× better |
Key Takeaway: 130x Token Efficiency and 2.2x Retrieval Precision
The most striking metric is the 130× difference in token efficiency. Vector RAG typically dumps full file contents into the context window with 8,775 tokens per query on average, meaning a 500-line test file weighs the same as a a 50-line interface definition.
Agentic Search, conversely, returns targeted answers with specific file paths, consuming only 72 tokens per query. For example:
"OAuth2 is implemented in packages/core/src/code_assist/oauth2.ts. See also the MCP OAuth provider in packages/core/src/mcp/oauth-provider.ts."
Agentic Search achieves 2.2× higher precision (0.117 vs 0.053).
The reason is because Vector RAG can't tell current code from historical artifacts. It sees AuthController.ts and Auth_v2_migration.ts as equally relevant because they share keywords. In contrast, the Context Tree maintains an accurate snapshot of the system's current status. Instead of just storing code, it captures the active implementation alongside key decisions in natural language that explain why the code arrived at this state. This ensures the agent builds upon the live architecture rather than hallucinating based on dead code or deprecated migration scripts.
4. Why Vector RAG Breaks: The "Similarity" Trap
Through our research, we identified three primary failure modes where similarity-based retrieval actively degrades agent performance.
Failure Mode #1: Pattern Matching vs. Architectural Relevance
Codebases are full of repeated patterns: error handling, logging, and authentication checks. If an engineer asks to update the auth controller a Vector RAG system will retrieve any file containing "auth," "user," or "controller." This often includes HTTP middleware, database utilities, and unrelated unit tests. They all score high on similarity because they share keywords, but they lack architectural relevance.
Failure Mode #2: The Museum Problem
Embeddings struggle to distinguish between the current state of the code and historical artifacts. In a messy production environment, AuthController.ts (active) and Old_Auth_Backup.ts (deprecated) often contain identical class names and function signatures. To an embedding model, they look nearly identical. This leads agents to import from dead code or hallucinate based on deprecated logic.
Failure Mode #3: Context Dilution
Most Vector RAG systems rely on a fixed top-k retrieval (e.g., top 5). This approach lacks nuance:
• Simple Query: "Where is OAuth2 defined?" (Needs 1 file) → RAG returns 5 files (80% noise).
• Complex Query: "Find all auth-related files." (Needs 15 files) → RAG returns 5 files (Significant context missing).
5. The Solution: Context Tree and Agentic Search
ByteRover 3.0 solves these issues by structuring memory the way engineers structure mental models: hierarchically.
Structured Knowledge Storage
Instead of a flat index, the Context Tree organizes the codebase into a navigable file system structure within .brv/context-tree/ .
.brv/context-tree/ ├── structure/ │ ├── authentication/ │ │ ├── oauth2/ │ │ │ └── oauth2-impl.md → Implementation: oauth2.ts, oauth-provider.ts │ │ └── api-keys/ │ │ └── storage-strategy.md → Implementation: apiKeyCredentialStorage.ts │ └── mcp/ │ └── integration.md → Related: @structure/authentication/oauth2
Intent-Driven Retrieval
When a query enters the system, Agentic Search does not look for keywords. It parses intent:
Analyze Request: "Add a new auth method."
Map to Domain: Identify the
structure/authenticationdomain.Traverse Relationships: Follow explicit links (e.g.,
@structure/authentication/oauth2) to pull in necessary dependencies like the MCP provider.
This results in an accurate snapshot of what is current, alongside the reasoning for why the code exists, without the noise of deprecated backups or unrelated test files.
6. Conclusion
The transition from Vector RAG to Context Trees represents a fundamental shift in how we engineer AI coding agents. To be effective partners, agents must respect that code is a sophisticated tree with architectural boundaries, not merely a collection of text chunks.
By adopting a domain-structured memory architecture, engineering teams can significantly reduce token costs, eliminate hallucinations caused by "dead code," and improve the reasoning capabilities of their coding agents.
Try It Yourself
Learn more about Context Tree and Agentic Search: ByteRover
All code, data, and visualizations are open sourced in this repo